 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Impute? Imputation before and during cross-validation
Oct 01, 2020
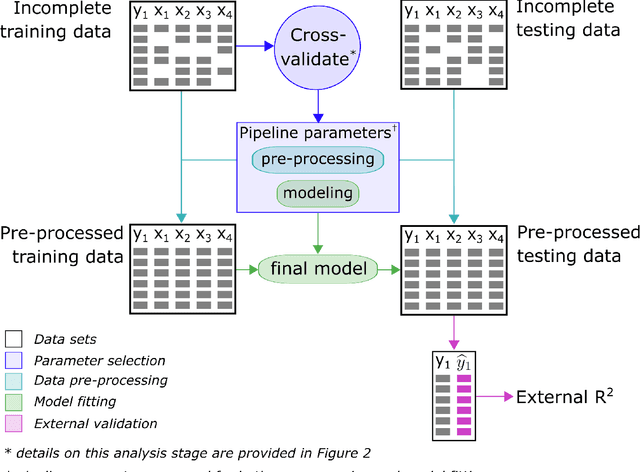
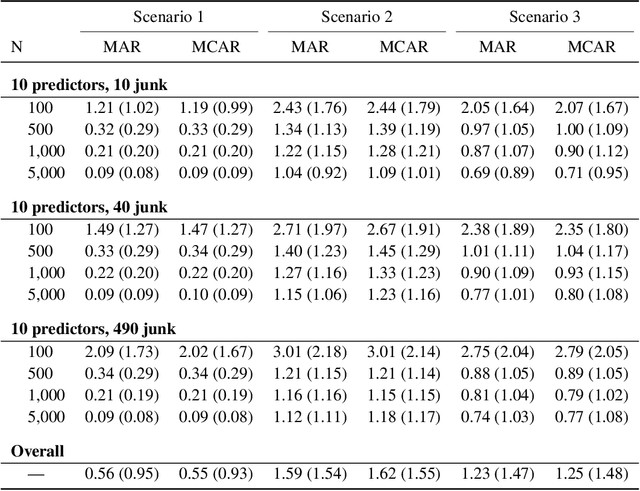
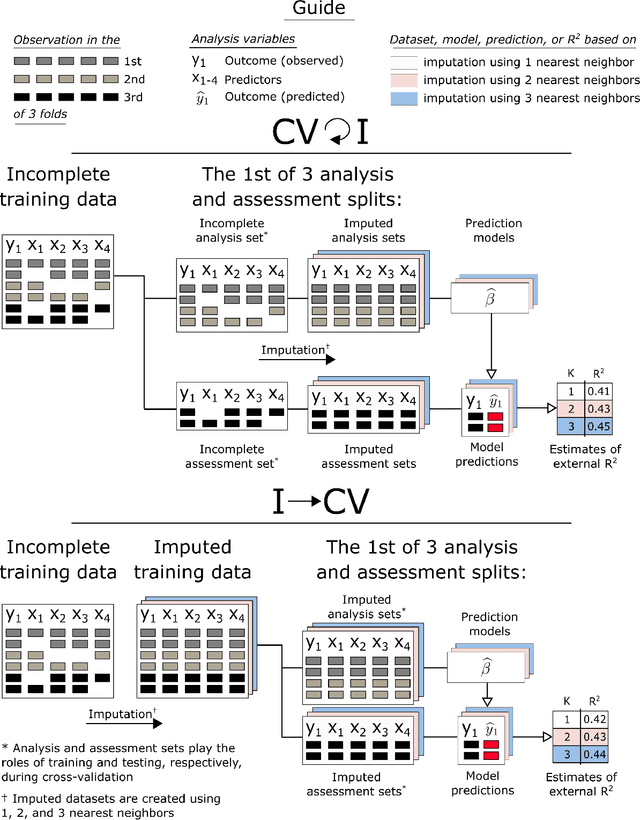
Cross-validation (CV) is a technique used to estimate generalization error for prediction models. For pipeline modeling algorithms (i.e. modeling procedures with multiple steps), it has been recommended the entire sequence of steps be carried out during each replicate of CV to mimic the application of the entire pipeline to an external testing set. While theoretically sound, following this recommendation can lead to high computational costs when a pipeline modeling algorithm includes computationally expensive operations, e.g. imputation of missing values. There is a general belief that unsupervised variable selection (i.e. ignoring the outcome) can be applied before conducting CV without incurring bias, but there is less consensus for unsupervised imputation of missing values. We empirically assessed whether conducting unsupervised imputation prior to CV would result in biased estimates of generalization error or result in poorly selected tuning parameters and thus degrade the external performance of downstream models. Results show that despite optimistic bias, the reduced variance of imputation before CV compared to imputation during each replicate of CV leads to a lower overall root mean squared error for estimation of the true external R-squared and the performance of models tuned using CV with imputation before versus during each replication is minimally different. In conclusion, unsupervised imputation before CV appears valid in certain settings and may be a helpful strategy that enables analysts to use more flexible imputation techniques without incurring high computational costs.
A unified approach for inference on algorithm-agnostic variable importance
Apr 07, 2020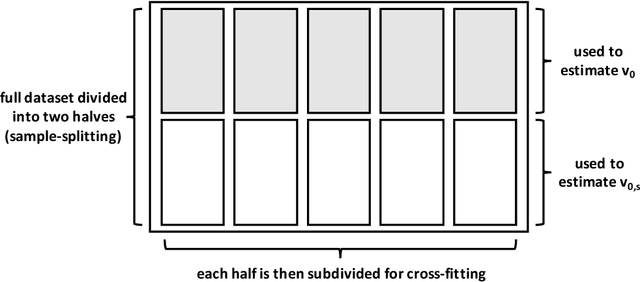

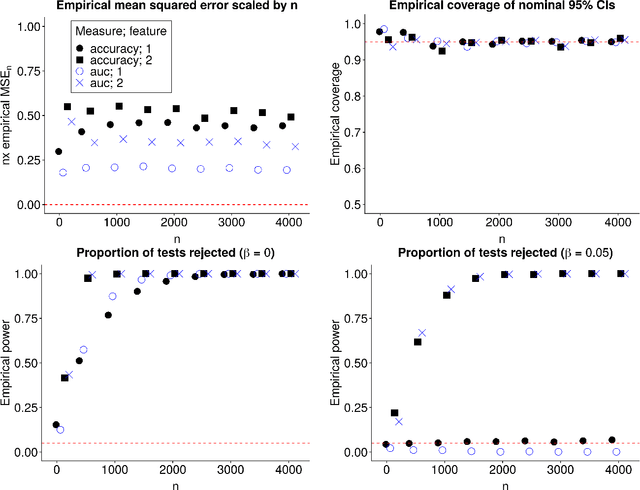

In many applications, it is of interest to assess the relative contribution of features (or subsets of features) toward the goal of predicting a response -- in other words, to gauge the variable importance of features. Most recent work on variable importance assessment has focused on describing the importance of features within the confines of a given prediction algorithm. However, such assessment does not necessarily characterize the prediction potential of features, and may provide a misleading reflection of the intrinsic value of these features. To address this limitation, we propose a general framework for nonparametric inference on interpretable algorithm-agnostic variable importance. We define variable importance as a population-level contrast between the oracle predictiveness of all available features versus all features except those under consideration. We propose a nonparametric efficient estimation procedure that allows the construction of valid confidence intervals, even when machine learning techniques are used. We also outline a valid strategy for testing the null importance hypothesis. Through simulations, we show that our proposal has good operating characteristics, and we illustrate its use with data from a study of an antibody against HIV-1 infection.