 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Impute? Imputation before and during cross-validation
Paper and Code

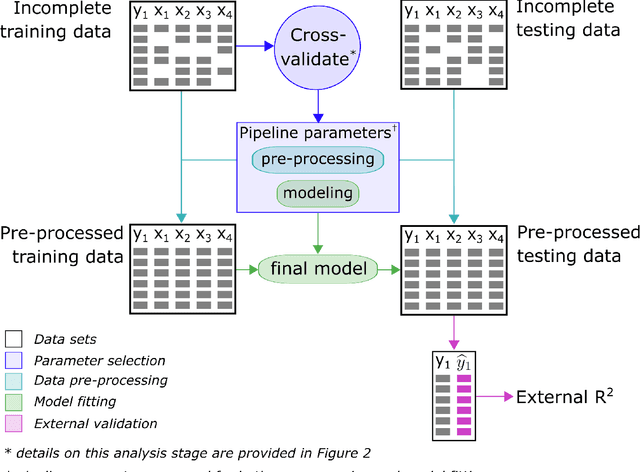
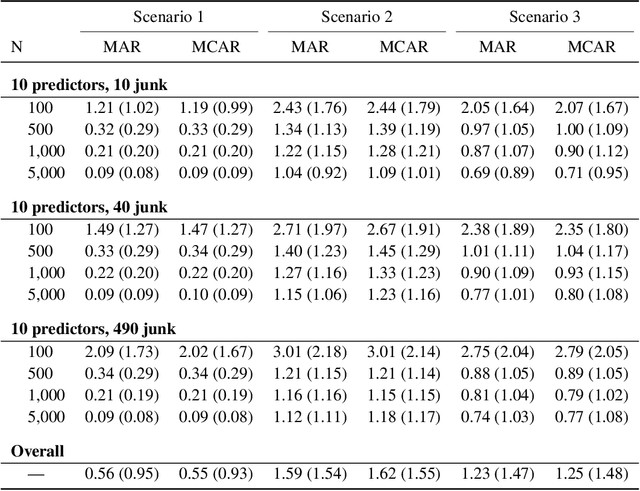
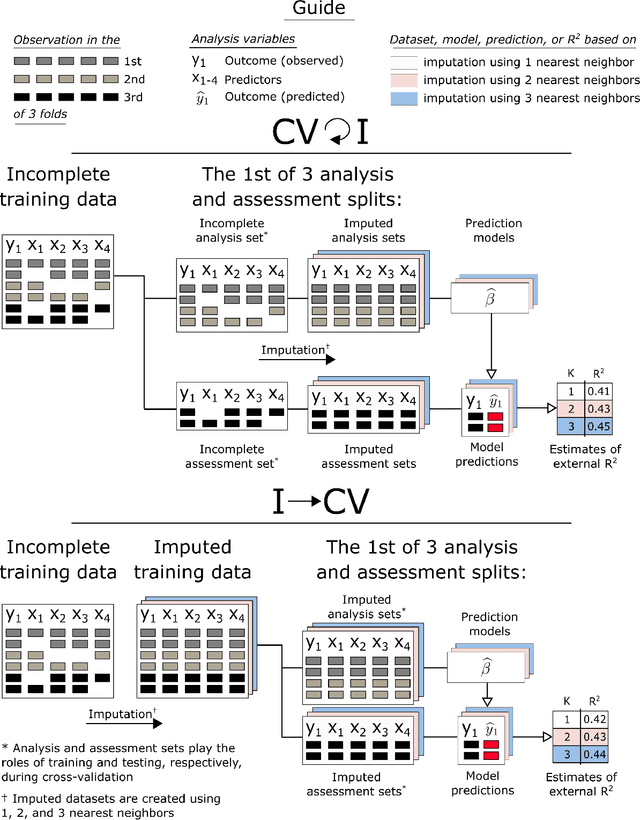
Cross-validation (CV) is a technique used to estimate generalization error for prediction models. For pipeline modeling algorithms (i.e. modeling procedures with multiple steps), it has been recommended the entire sequence of steps be carried out during each replicate of CV to mimic the application of the entire pipeline to an external testing set. While theoretically sound, following this recommendation can lead to high computational costs when a pipeline modeling algorithm includes computationally expensive operations, e.g. imputation of missing values. There is a general belief that unsupervised variable selection (i.e. ignoring the outcome) can be applied before conducting CV without incurring bias, but there is less consensus for unsupervised imputation of missing values. We empirically assessed whether conducting unsupervised imputation prior to CV would result in biased estimates of generalization error or result in poorly selected tuning parameters and thus degrade the external performance of downstream models. Results show that despite optimistic bias, the reduced variance of imputation before CV compared to imputation during each replicate of CV leads to a lower overall root mean squared error for estimation of the true external R-squared and the performance of models tuned using CV with imputation before versus during each replication is minimally different. In conclusion, unsupervised imputation before CV appears valid in certain settings and may be a helpful strategy that enables analysts to use more flexible imputation techniques without incurring high computational costs.