 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGanFinger: GAN-Based Fingerprint Generation for Deep Neural Network Ownership Verification
Dec 25, 2023



Deep neural networks (DNNs) are extensively employed in a wide range of application scenarios. Generally, training a commercially viable neural network requires significant amounts of data and computing resources, and it is easy for unauthorized users to use the networks illegally. Therefore, network ownership verification has become one of the most crucial steps in safeguarding digital assets. To verify the ownership of networks, the existing network fingerprinting approaches perform poorly in the aspects of efficiency, stealthiness, and discriminability. To address these issues, we propose a network fingerprinting approach, named as GanFinger, to construct the network fingerprints based on the network behavior, which is characterized by network outputs of pairs of original examples and conferrable adversarial examples. Specifically, GanFinger leverages Generative Adversarial Networks (GANs) to effectively generate conferrable adversarial examples with imperceptible perturbations. These examples can exhibit identical outputs on copyrighted and pirated networks while producing different results on irrelevant networks. Moreover, to enhance the accuracy of fingerprint ownership verification, the network similarity is computed based on the accuracy-robustness distance of fingerprint examples'outputs. To evaluate the performance of GanFinger, we construct a comprehensive benchmark consisting of 186 networks with five network structures and four popular network post-processing techniques. The benchmark experiments demonstrate that GanFinger significantly outperforms the state-of-the-arts in efficiency, stealthiness, and discriminability. It achieves a remarkable 6.57 times faster in fingerprint generation and boosts the ARUC value by 0.175, resulting in a relative improvement of about 26%.
Fast Reinforcement Learning for Anti-jamming Communications
Feb 13, 2020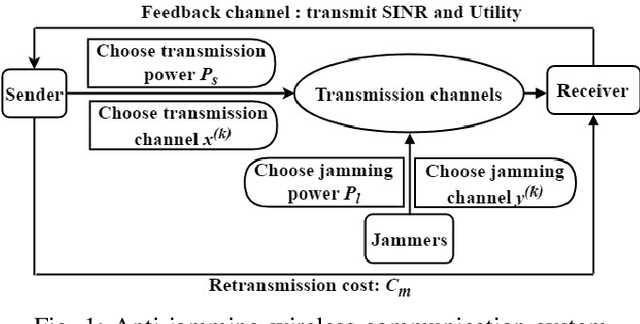
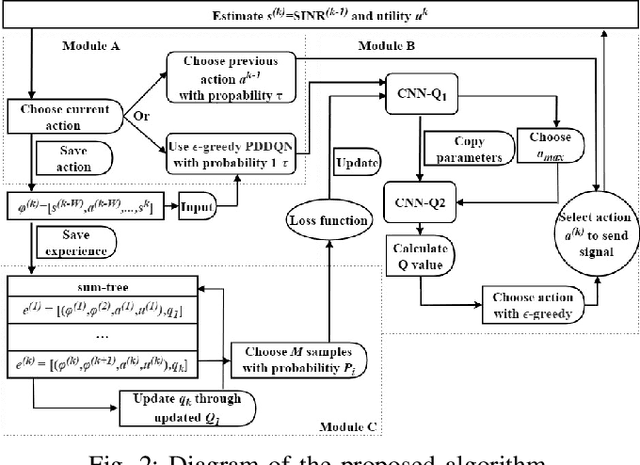
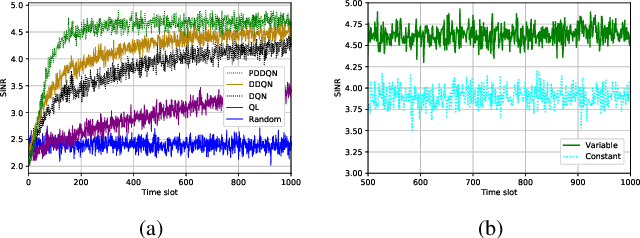
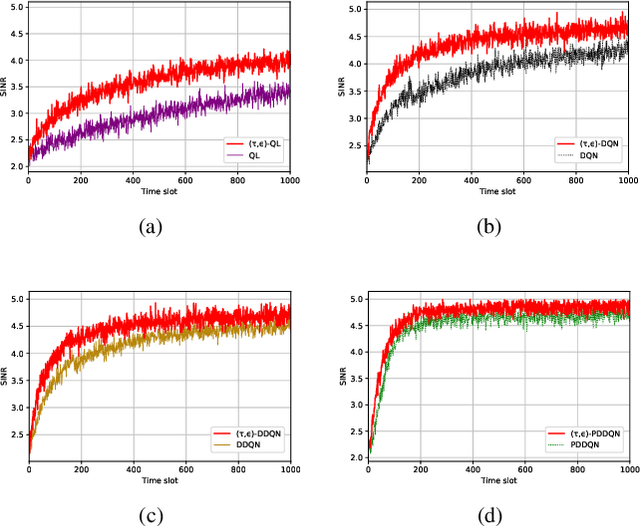
This letter presents a fast reinforcement learning algorithm for anti-jamming communications which chooses previous action with probability $\tau$ and applies $\epsilon$-greedy with probability $(1-\tau)$. A dynamic threshold based on the average value of previous several actions is designed and probability $\tau$ is formulated as a Gaussian-like function to guide the wireless devices. As a concrete example, the proposed algorithm is implemented in a wireless communication system against multiple jammers. Experimental results demonstrate that the proposed algorithm exceeds Q-learing, deep Q-networks (DQN), double DQN (DDQN), and prioritized experience reply based DDQN (PDDQN), in terms of signal-to-interference-plus-noise ratio and convergence rate.