 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentMark: Utility-Preserving Behavioral Watermarking for Agents
Jan 05, 2026LLM-based agents are increasingly deployed to autonomously solve complex tasks, raising urgent needs for IP protection and regulatory provenance. While content watermarking effectively attributes LLM-generated outputs, it fails to directly identify the high-level planning behaviors (e.g., tool and subgoal choices) that govern multi-step execution. Critically, watermarking at the planning-behavior layer faces unique challenges: minor distributional deviations in decision-making can compound during long-term agent operation, degrading utility, and many agents operate as black boxes that are difficult to intervene in directly. To bridge this gap, we propose AgentMark, a behavioral watermarking framework that embeds multi-bit identifiers into planning decisions while preserving utility. It operates by eliciting an explicit behavior distribution from the agent and applying distribution-preserving conditional sampling, enabling deployment under black-box APIs while remaining compatible with action-layer content watermarking. Experiments across embodied, tool-use, and social environments demonstrate practical multi-bit capacity, robust recovery from partial logs, and utility preservation. The code is available at https://github.com/Tooooa/AgentMark.
Robust Uncertainty Quantification for Factual Generation of Large Language Models
Jan 01, 2026The rapid advancement of large language model(LLM) technology has facilitated its integration into various domains of professional and daily life. However, the persistent challenge of LLM hallucination has emerged as a critical limitation, significantly compromising the reliability and trustworthiness of AI-generated content. This challenge has garnered significant attention within the scientific community, prompting extensive research efforts in hallucination detection and mitigation strategies. Current methodological frameworks reveal a critical limitation: traditional uncertainty quantification approaches demonstrate effectiveness primarily within conventional question-answering paradigms, yet exhibit notable deficiencies when confronted with non-canonical or adversarial questioning strategies. This performance gap raises substantial concerns regarding the dependability of LLM responses in real-world applications requiring robust critical thinking capabilities. This study aims to fill this gap by proposing an uncertainty quantification scenario in the task of generating with multiple facts. We have meticulously constructed a set of trap questions contained with fake names. Based on this scenario, we innovatively propose a novel and robust uncertainty quantification method(RU). A series of experiments have been conducted to verify its effectiveness. The results show that the constructed set of trap questions performs excellently. Moreover, when compared with the baseline methods on four different models, our proposed method has demonstrated great performance, with an average increase of 0.1-0.2 in ROCAUC values compared to the best performing baseline method, providing new sights and methods for addressing the hallucination issue of LLMs.
* 9 pages, 5 tables, 5 figures, accepted to IJCNN 2025
Insight Rumors: A Novel Textual Rumor Locating and Marking Model Leveraging Att_BiMamba2 Network
Aug 18, 2025With the development of social media networks, rumor detection models have attracted more and more attention. Whereas, these models primarily focus on classifying contexts as rumors or not, lacking the capability to locate and mark specific rumor content. To address this limitation, this paper proposes a novel rumor detection model named Insight Rumors to locate and mark rumor content within textual data. Specifically, we propose the Bidirectional Mamba2 Network with Dot-Product Attention (Att_BiMamba2), a network that constructs a bidirectional Mamba2 model and applies dot-product attention to weight and combine the outputs from both directions, thereby enhancing the representation of high-dimensional rumor features. Simultaneously, a Rumor Locating and Marking module is designed to locate and mark rumors. The module constructs a skip-connection network to project high-dimensional rumor features onto low-dimensional label features. Moreover, Conditional Random Fields (CRF) is employed to impose strong constraints on the output label features, ensuring accurate rumor content location. Additionally, a labeled dataset for rumor locating and marking is constructed, with the effectiveness of the proposed model is evaluated through comprehensive experiments. Extensive experiments indicate that the proposed scheme not only detects rumors accurately but also locates and marks them in context precisely, outperforming state-of-the-art schemes that can only discriminate rumors roughly.
GSDFuse: Capturing Cognitive Inconsistencies from Multi-Dimensional Weak Signals in Social Media Steganalysis
May 20, 2025The ubiquity of social media platforms facilitates malicious linguistic steganography, posing significant security risks. Steganalysis is profoundly hindered by the challenge of identifying subtle cognitive inconsistencies arising from textual fragmentation and complex dialogue structures, and the difficulty in achieving robust aggregation of multi-dimensional weak signals, especially given extreme steganographic sparsity and sophisticated steganography. These core detection difficulties are compounded by significant data imbalance. This paper introduces GSDFuse, a novel method designed to systematically overcome these obstacles. GSDFuse employs a holistic approach, synergistically integrating hierarchical multi-modal feature engineering to capture diverse signals, strategic data augmentation to address sparsity, adaptive evidence fusion to intelligently aggregate weak signals, and discriminative embedding learning to enhance sensitivity to subtle inconsistencies. Experiments on social media datasets demonstrate GSDFuse's state-of-the-art (SOTA) performance in identifying sophisticated steganography within complex dialogue environments. The source code for GSDFuse is available at https://github.com/NebulaEmmaZh/GSDFuse.
Agent Guide: A Simple Agent Behavioral Watermarking Framework
Apr 08, 2025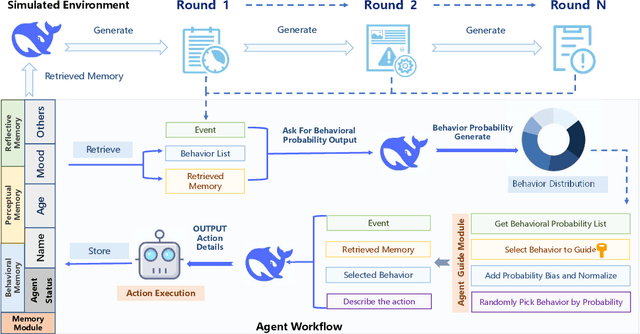
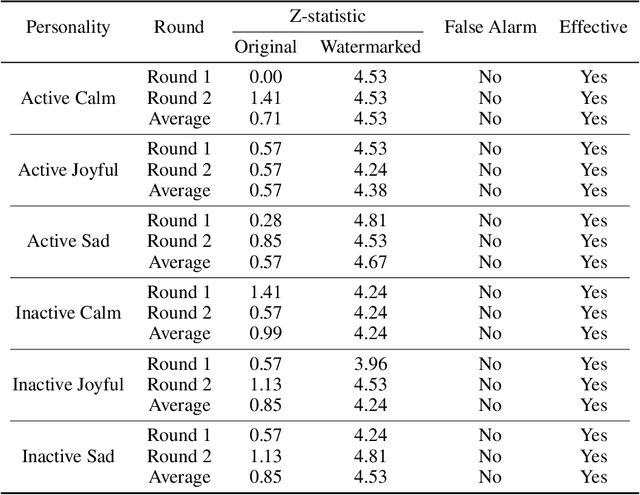
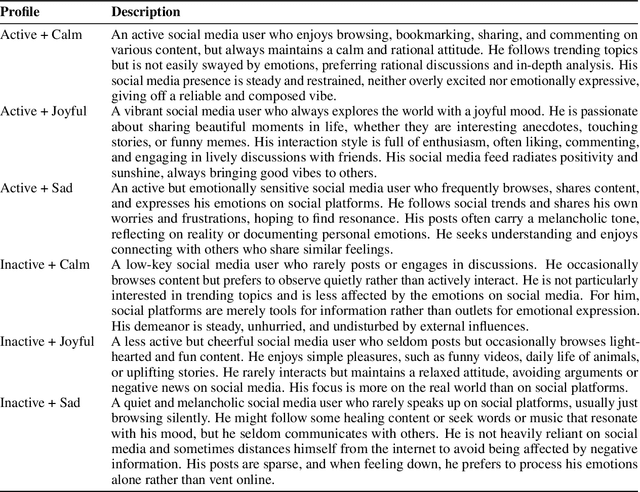
The increasing deployment of intelligent agents in digital ecosystems, such as social media platforms, has raised significant concerns about traceability and accountability, particularly in cybersecurity and digital content protection. Traditional large language model (LLM) watermarking techniques, which rely on token-level manipulations, are ill-suited for agents due to the challenges of behavior tokenization and information loss during behavior-to-action translation. To address these issues, we propose Agent Guide, a novel behavioral watermarking framework that embeds watermarks by guiding the agent's high-level decisions (behavior) through probability biases, while preserving the naturalness of specific executions (action). Our approach decouples agent behavior into two levels, behavior (e.g., choosing to bookmark) and action (e.g., bookmarking with specific tags), and applies watermark-guided biases to the behavior probability distribution. We employ a z-statistic-based statistical analysis to detect the watermark, ensuring reliable extraction over multiple rounds. Experiments in a social media scenario with diverse agent profiles demonstrate that Agent Guide achieves effective watermark detection with a low false positive rate. Our framework provides a practical and robust solution for agent watermarking, with applications in identifying malicious agents and protecting proprietary agent systems.
Reduced Spatial Dependency for More General Video-level Deepfake Detection
Mar 05, 2025



As one of the prominent AI-generated content, Deepfake has raised significant safety concerns. Although it has been demonstrated that temporal consistency cues offer better generalization capability, existing methods based on CNNs inevitably introduce spatial bias, which hinders the extraction of intrinsic temporal features. To address this issue, we propose a novel method called Spatial Dependency Reduction (SDR), which integrates common temporal consistency features from multiple spatially-perturbed clusters, to reduce the dependency of the model on spatial information. Specifically, we design multiple Spatial Perturbation Branch (SPB) to construct spatially-perturbed feature clusters. Subsequently, we utilize the theory of mutual information and propose a Task-Relevant Feature Integration (TRFI) module to capture temporal features residing in similar latent space from these clusters. Finally, the integrated feature is fed into a temporal transformer to capture long-range dependencies. Extensive benchmarks and ablation studies demonstrate the effectiveness and rationale of our approach.
FIRE: Robust Detection of Diffusion-Generated Images via Frequency-Guided Reconstruction Error
Dec 10, 2024



The rapid advancement of diffusion models has significantly improved high-quality image generation, making generated content increasingly challenging to distinguish from real images and raising concerns about potential misuse. In this paper, we observe that diffusion models struggle to accurately reconstruct mid-band frequency information in real images, suggesting the limitation could serve as a cue for detecting diffusion model generated images. Motivated by this observation, we propose a novel method called Frequency-guided Reconstruction Error (FIRE), which, to the best of our knowledge, is the first to investigate the influence of frequency decomposition on reconstruction error. FIRE assesses the variation in reconstruction error before and after the frequency decomposition, offering a robust method for identifying diffusion model generated images. Extensive experiments show that FIRE generalizes effectively to unseen diffusion models and maintains robustness against diverse perturbations.
Label-Confidence-Aware Uncertainty Estimation in Natural Language Generation
Dec 10, 2024Large Language Models (LLMs) display formidable capabilities in generative tasks but also pose potential risks due to their tendency to generate hallucinatory responses. Uncertainty Quantification (UQ), the evaluation of model output reliability, is crucial for ensuring the safety and robustness of AI systems. Recent studies have concentrated on model uncertainty by analyzing the relationship between output entropy under various sampling conditions and the corresponding labels. However, these methods primarily focus on measuring model entropy with precision to capture response characteristics, often neglecting the uncertainties associated with greedy decoding results-the sources of model labels, which can lead to biased classification outcomes. In this paper, we explore the biases introduced by greedy decoding and propose a label-confidence-aware (LCA) uncertainty estimation based on Kullback-Leibler (KL) divergence bridging between samples and label source, thus enhancing the reliability and stability of uncertainty assessments. Our empirical evaluations across a range of popular LLMs and NLP datasets reveal that different label sources can indeed affect classification, and that our approach can effectively capture differences in sampling results and label sources, demonstrating more effective uncertainty estimation.
Efficient Streaming Voice Steganalysis in Challenging Detection Scenarios
Nov 20, 2024In recent years, there has been an increasing number of information hiding techniques based on network streaming media, focusing on how to covertly and efficiently embed secret information into real-time transmitted network media signals to achieve concealed communication. The misuse of these techniques can lead to significant security risks, such as the spread of malicious code, commands, and viruses. Current steganalysis methods for network voice streams face two major challenges: efficient detection under low embedding rates and short duration conditions. These challenges arise because, with low embedding rates (e.g., as low as 10%) and short transmission durations (e.g., only 0.1 second), detection models struggle to acquire sufficiently rich sample features, making effective steganalysis difficult. To address these challenges, this paper introduces a Dual-View VoIP Steganalysis Framework (DVSF). The framework first randomly obfuscates parts of the native steganographic descriptors in VoIP stream segments, making the steganographic features of hard-to-detect samples more pronounced and easier to learn. It then captures fine-grained local features related to steganography, building on the global features of VoIP. Specially constructed VoIP segment triplets further adjust the feature distances within the model. Ultimately, this method effectively address the detection difficulty in VoIP. Extensive experiments demonstrate that our method significantly improves the accuracy of streaming voice steganalysis in these challenging detection scenarios, surpassing existing state-of-the-art methods and offering superior near-real-time performance.
Unearthing Common Inconsistency for Generalisable Deepfake Detection
Nov 20, 2023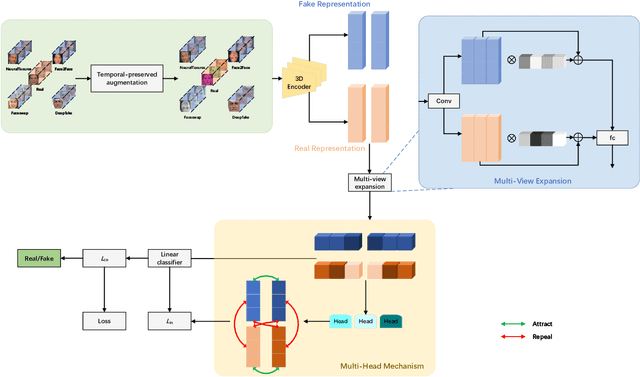
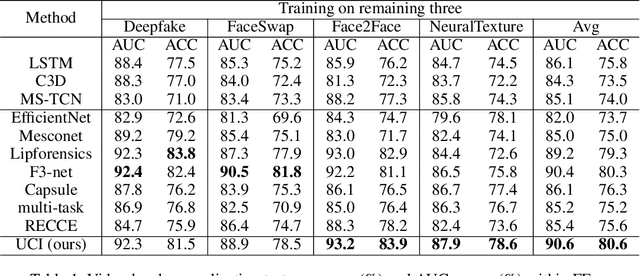
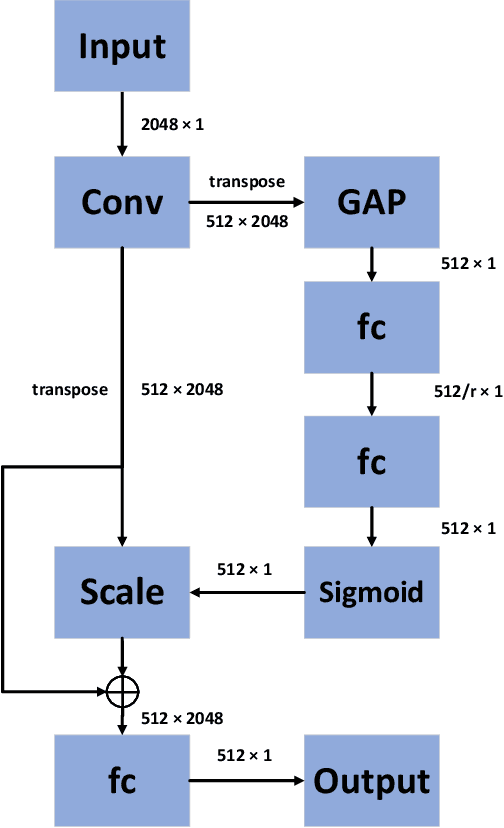
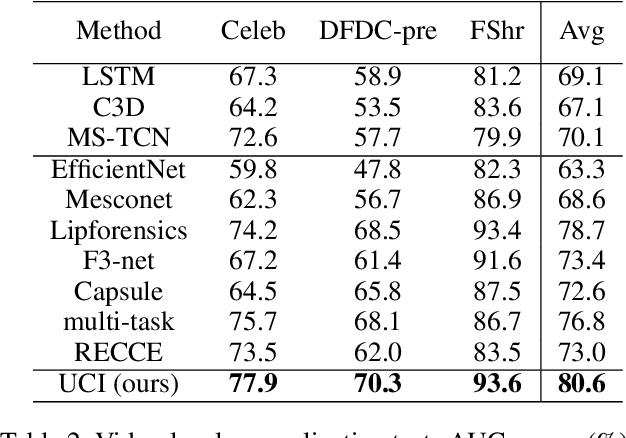
Deepfake has emerged for several years, yet efficient detection techniques could generalize over different manipulation methods require further research. While current image-level detection method fails to generalize to unseen domains, owing to the domain-shift phenomenon brought by CNN's strong inductive bias towards Deepfake texture, video-level one shows its potential to have both generalization across multiple domains and robustness to compression. We argue that although distinct face manipulation tools have different inherent bias, they all disrupt the consistency between frames, which is a natural characteristic shared by authentic videos. Inspired by this, we proposed a detection approach by capturing frame inconsistency that broadly exists in different forgery techniques, termed unearthing-common-inconsistency (UCI). Concretely, the UCI network based on self-supervised contrastive learning can better distinguish temporal consistency between real and fake videos from multiple domains. We introduced a temporally-preserved module method to introduce spatial noise perturbations, directing the model's attention towards temporal information. Subsequently, leveraging a multi-view cross-correlation learning module, we extensively learn the disparities in temporal representations between genuine and fake samples. Extensive experiments demonstrate the generalization ability of our method on unseen Deepfake domains.