 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReduced Spatial Dependency for More General Video-level Deepfake Detection
Mar 05, 2025



As one of the prominent AI-generated content, Deepfake has raised significant safety concerns. Although it has been demonstrated that temporal consistency cues offer better generalization capability, existing methods based on CNNs inevitably introduce spatial bias, which hinders the extraction of intrinsic temporal features. To address this issue, we propose a novel method called Spatial Dependency Reduction (SDR), which integrates common temporal consistency features from multiple spatially-perturbed clusters, to reduce the dependency of the model on spatial information. Specifically, we design multiple Spatial Perturbation Branch (SPB) to construct spatially-perturbed feature clusters. Subsequently, we utilize the theory of mutual information and propose a Task-Relevant Feature Integration (TRFI) module to capture temporal features residing in similar latent space from these clusters. Finally, the integrated feature is fed into a temporal transformer to capture long-range dependencies. Extensive benchmarks and ablation studies demonstrate the effectiveness and rationale of our approach.
FIRE: Robust Detection of Diffusion-Generated Images via Frequency-Guided Reconstruction Error
Dec 10, 2024



The rapid advancement of diffusion models has significantly improved high-quality image generation, making generated content increasingly challenging to distinguish from real images and raising concerns about potential misuse. In this paper, we observe that diffusion models struggle to accurately reconstruct mid-band frequency information in real images, suggesting the limitation could serve as a cue for detecting diffusion model generated images. Motivated by this observation, we propose a novel method called Frequency-guided Reconstruction Error (FIRE), which, to the best of our knowledge, is the first to investigate the influence of frequency decomposition on reconstruction error. FIRE assesses the variation in reconstruction error before and after the frequency decomposition, offering a robust method for identifying diffusion model generated images. Extensive experiments show that FIRE generalizes effectively to unseen diffusion models and maintains robustness against diverse perturbations.
Unearthing Common Inconsistency for Generalisable Deepfake Detection
Nov 20, 2023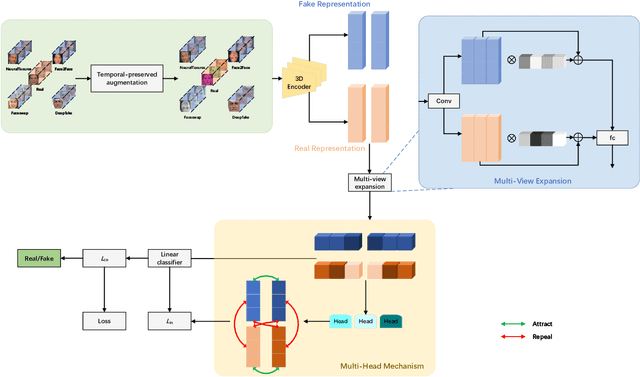
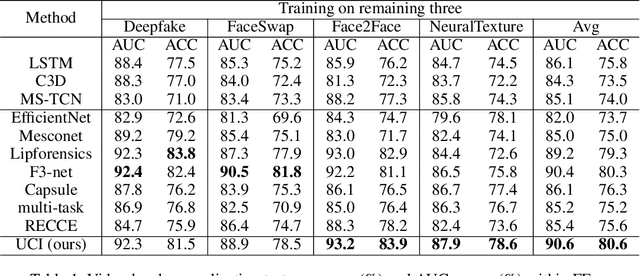
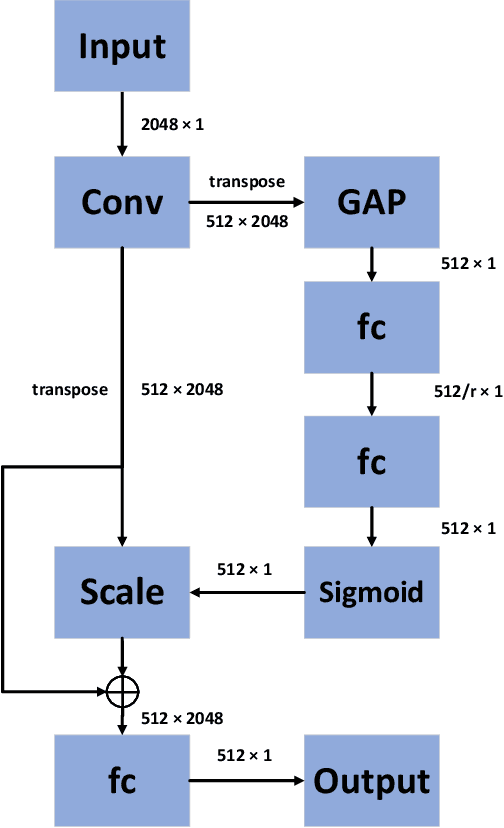
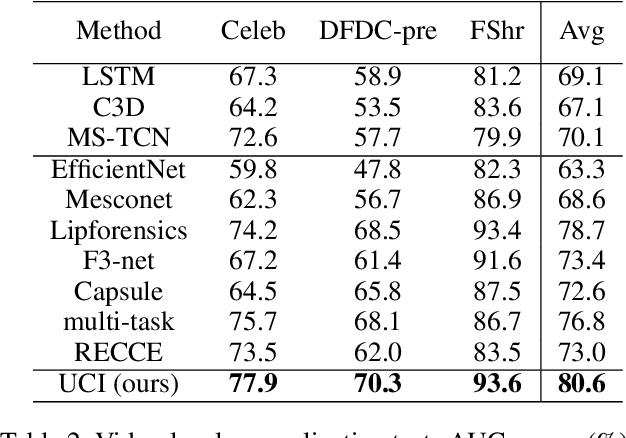
Deepfake has emerged for several years, yet efficient detection techniques could generalize over different manipulation methods require further research. While current image-level detection method fails to generalize to unseen domains, owing to the domain-shift phenomenon brought by CNN's strong inductive bias towards Deepfake texture, video-level one shows its potential to have both generalization across multiple domains and robustness to compression. We argue that although distinct face manipulation tools have different inherent bias, they all disrupt the consistency between frames, which is a natural characteristic shared by authentic videos. Inspired by this, we proposed a detection approach by capturing frame inconsistency that broadly exists in different forgery techniques, termed unearthing-common-inconsistency (UCI). Concretely, the UCI network based on self-supervised contrastive learning can better distinguish temporal consistency between real and fake videos from multiple domains. We introduced a temporally-preserved module method to introduce spatial noise perturbations, directing the model's attention towards temporal information. Subsequently, leveraging a multi-view cross-correlation learning module, we extensively learn the disparities in temporal representations between genuine and fake samples. Extensive experiments demonstrate the generalization ability of our method on unseen Deepfake domains.