 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous K-space Recovery Network with Image Guidance for Fast MRI Reconstruction
Nov 18, 2024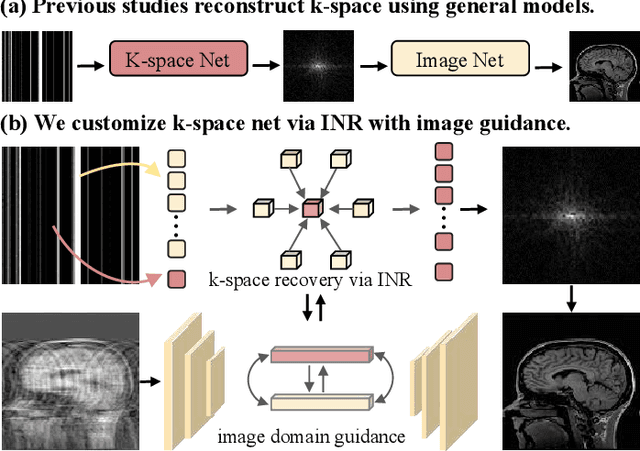
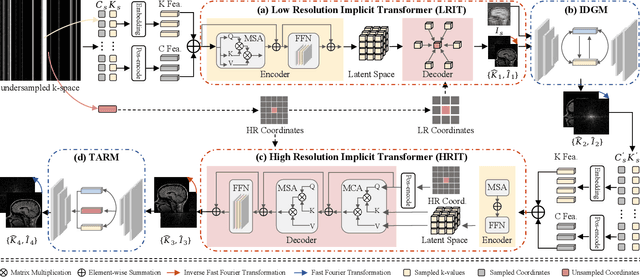
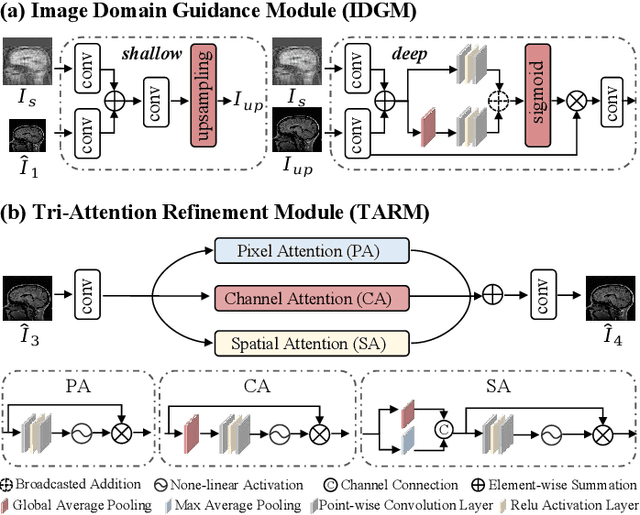
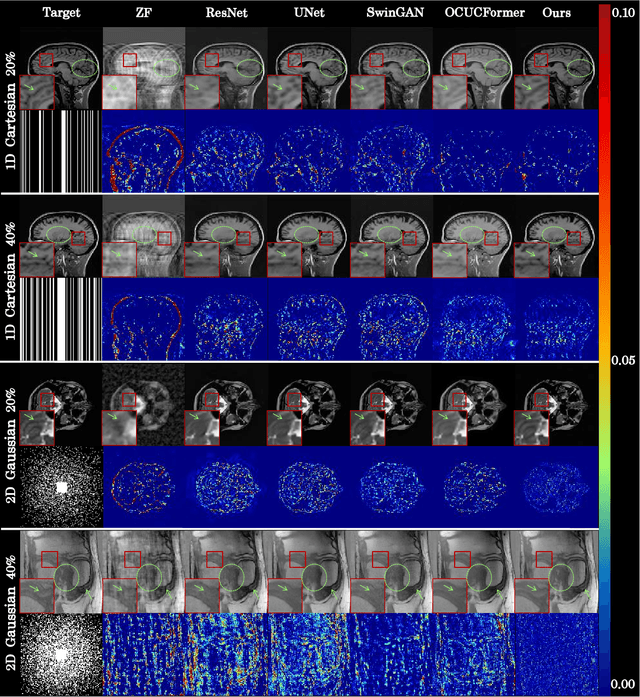
Magnetic resonance imaging (MRI) is a crucial tool for clinical diagnosis while facing the challenge of long scanning time. To reduce the acquisition time, fast MRI reconstruction aims to restore high-quality images from the undersampled k-space. Existing methods typically train deep learning models to map the undersampled data to artifact-free MRI images. However, these studies often overlook the unique properties of k-space and directly apply general networks designed for image processing to k-space recovery, leaving the precise learning of k-space largely underexplored. In this work, we propose a continuous k-space recovery network from a new perspective of implicit neural representation with image domain guidance, which boosts the performance of MRI reconstruction. Specifically, (1) an implicit neural representation based encoder-decoder structure is customized to continuously query unsampled k-values. (2) an image guidance module is designed to mine the semantic information from the low-quality MRI images to further guide the k-space recovery. (3) a multi-stage training strategy is proposed to recover dense k-space progressively. Extensive experiments conducted on CC359, fastMRI, and IXI datasets demonstrate the effectiveness of our method and its superiority over other competitors.
Local Implicit Wavelet Transformer for Arbitrary-Scale Super-Resolution
Nov 10, 2024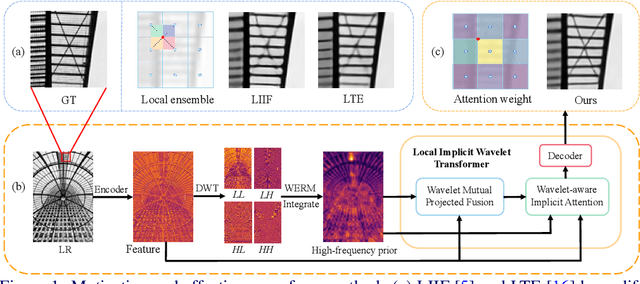
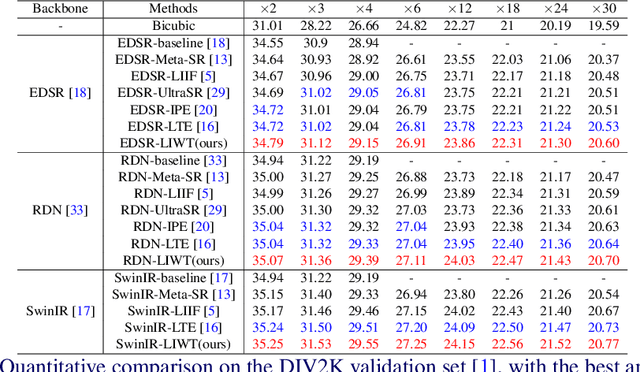


Implicit neural representations have recently demonstrated promising potential in arbitrary-scale Super-Resolution (SR) of images. Most existing methods predict the pixel in the SR image based on the queried coordinate and ensemble nearby features, overlooking the importance of incorporating high-frequency prior information in images, which results in limited performance in reconstructing high-frequency texture details in images. To address this issue, we propose the Local Implicit Wavelet Transformer (LIWT) to enhance the restoration of high-frequency texture details. Specifically, we decompose the features extracted by an encoder into four sub-bands containing different frequency information using Discrete Wavelet Transform (DWT). We then introduce the Wavelet Enhanced Residual Module (WERM) to transform these four sub-bands into high-frequency priors, followed by utilizing the Wavelet Mutual Projected Fusion (WMPF) and the Wavelet-aware Implicit Attention (WIA) to fully exploit the high-frequency prior information for recovering high-frequency details in images. We conducted extensive experiments on benchmark datasets to validate the effectiveness of LIWT. Both qualitative and quantitative results demonstrate that LIWT achieves promising performance in arbitrary-scale SR tasks, outperforming other state-of-the-art methods. The code is available at https://github.com/dmhdmhdmh/LIWT.
Separate and Conquer: Decoupling Co-occurrence via Decomposition and Representation for Weakly Supervised Semantic Segmentation
Feb 29, 2024



Attributed to the frequent coupling of co-occurring objects and the limited supervision from image-level labels, the challenging co-occurrence problem is widely present and leads to false activation of objects in weakly supervised semantic segmentation (WSSS). In this work, we devise a 'Separate and Conquer' scheme SeCo to tackle this issue from dimensions of image space and feature space. In the image space, we propose to 'separate' the co-occurring objects with image decomposition by subdividing images into patches. Importantly, we assign each patch a category tag from Class Activation Maps (CAMs), which spatially helps remove the co-context bias and guide the subsequent representation. In the feature space, we propose to 'conquer' the false activation by enhancing semantic representation with multi-granularity knowledge contrast. To this end, a dual-teacher-single-student architecture is designed and tag-guided contrast is conducted to guarantee the correctness of knowledge and further facilitate the discrepancy among co-occurring objects. We streamline the multi-staged WSSS pipeline end-to-end and tackle co-occurrence without external supervision. Extensive experiments are conducted, validating the efficiency of our method tackling co-occurrence and the superiority over previous single-staged and even multi-staged competitors on PASCAL VOC and MS COCO. Code will be available at https://github.com/zwyang6/SeCo.git.
Towards Arbitrary-Scale Histopathology Image Super-resolution: An Efficient Dual-branch Framework via Implicit Self-texture Enhancement
Jan 28, 2024High-quality whole-slide scanners are expensive, complex, and time-consuming, thus limiting the acquisition and utilization of high-resolution pathology whole-slide images in daily clinical work. Deep learning-based single-image super-resolution techniques are an effective way to solve this problem by synthesizing high-resolution images from low-resolution ones. However, the existing super-resolution models applied in pathology images can only work in fixed integer magnifications, significantly decreasing their applicability. Though methods based on implicit neural representation have shown promising results in arbitrary-scale super-resolution of natural images, applying them directly to pathology images is inadequate because they have unique fine-grained image textures different from natural images. Thus, we propose an Implicit Self-Texture Enhancement-based dual-branch framework (ISTE) for arbitrary-scale super-resolution of pathology images to address this challenge. ISTE contains a pixel learning branch and a texture learning branch, which first learn pixel features and texture features, respectively. Then, we design a two-stage texture enhancement strategy to fuse the features from the two branches to obtain the super-resolution results, where the first stage is feature-based texture enhancement, and the second stage is spatial-domain-based texture enhancement. Extensive experiments on three public datasets show that ISTE outperforms existing fixed-scale and arbitrary-scale algorithms at multiple magnifications and helps to improve downstream task performance. To the best of our knowledge, this is the first work to achieve arbitrary-scale super-resolution in pathology images. Codes will be available.
Towards Arbitrary-scale Histopathology Image Super-resolution: An Efficient Dual-branch Framework based on Implicit Self-texture Enhancement
Apr 09, 2023Existing super-resolution models for pathology images can only work in fixed integer magnifications and have limited performance. Though implicit neural network-based methods have shown promising results in arbitrary-scale super-resolution of natural images, it is not effective to directly apply them in pathology images, because pathology images have special fine-grained image textures different from natural images. To address this challenge, we propose a dual-branch framework with an efficient self-texture enhancement mechanism for arbitrary-scale super-resolution of pathology images. Extensive experiments on two public datasets show that our method outperforms both existing fixed-scale and arbitrary-scale algorithms. To the best of our knowledge, this is the first work to achieve arbitrary-scale super-resolution in the field of pathology images. Codes will be available.