 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDFP: Data-dependent Frequency Prompt for Source Free Domain Adaptation of Medical Image Segmentation
May 15, 2025Domain adaptation addresses the challenge of model performance degradation caused by domain gaps. In the typical setup for unsupervised domain adaptation, labeled data from a source domain and unlabeled data from a target domain are used to train a target model. However, access to labeled source domain data, particularly in medical datasets, can be restricted due to privacy policies. As a result, research has increasingly shifted to source-free domain adaptation (SFDA), which requires only a pretrained model from the source domain and unlabeled data from the target domain data for adaptation. Existing SFDA methods often rely on domain-specific image style translation and self-supervision techniques to bridge the domain gap and train the target domain model. However, the quality of domain-specific style-translated images and pseudo-labels produced by these methods still leaves room for improvement. Moreover, training the entire model during adaptation can be inefficient under limited supervision. In this paper, we propose a novel SFDA framework to address these challenges. Specifically, to effectively mitigate the impact of domain gap in the initial training phase, we introduce preadaptation to generate a preadapted model, which serves as an initialization of target model and allows for the generation of high-quality enhanced pseudo-labels without introducing extra parameters. Additionally, we propose a data-dependent frequency prompt to more effectively translate target domain images into a source-like style. To further enhance adaptation, we employ a style-related layer fine-tuning strategy, specifically designed for SFDA, to train the target model using the prompted target domain images and pseudo-labels. Extensive experiments on cross-modality abdominal and cardiac SFDA segmentation tasks demonstrate that our proposed method outperforms existing state-of-the-art methods.
Weakly Semi-supervised Whole Slide Image Classification by Two-level Cross Consistency Supervision
Apr 16, 2025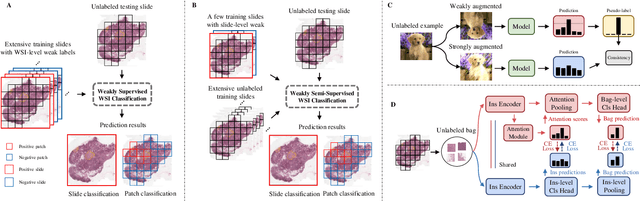
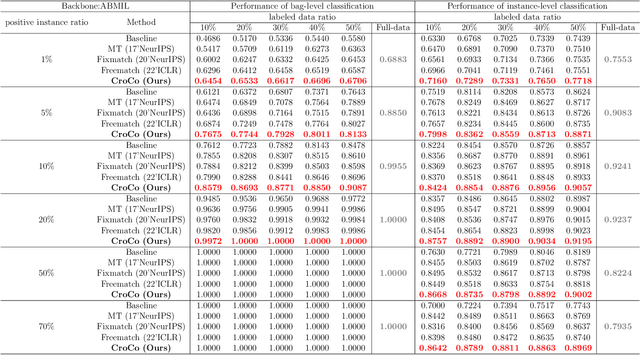
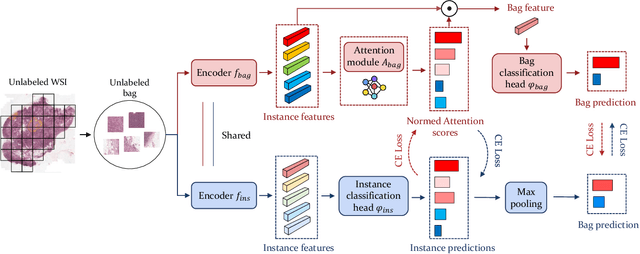
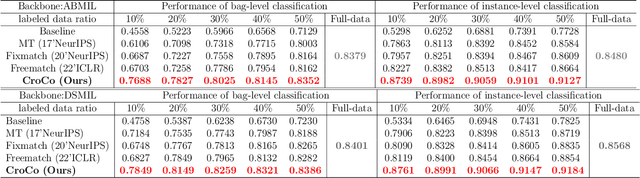
Computer-aided Whole Slide Image (WSI) classification has the potential to enhance the accuracy and efficiency of clinical pathological diagnosis. It is commonly formulated as a Multiple Instance Learning (MIL) problem, where each WSI is treated as a bag and the small patches extracted from the WSI are considered instances within that bag. However, obtaining labels for a large number of bags is a costly and time-consuming process, particularly when utilizing existing WSIs for new classification tasks. This limitation renders most existing WSI classification methods ineffective. To address this issue, we propose a novel WSI classification problem setting, more aligned with clinical practice, termed Weakly Semi-supervised Whole slide image Classification (WSWC). In WSWC, a small number of bags are labeled, while a significant number of bags remain unlabeled. The MIL nature of the WSWC problem, coupled with the absence of patch labels, distinguishes it from typical semi-supervised image classification problems, making existing algorithms for natural images unsuitable for directly solving the WSWC problem. In this paper, we present a concise and efficient framework, named CroCo, to tackle the WSWC problem through two-level Cross Consistency supervision. CroCo comprises two heterogeneous classifier branches capable of performing both instance classification and bag classification. The fundamental idea is to establish cross-consistency supervision at both the bag-level and instance-level between the two branches during training. Extensive experiments conducted on four datasets demonstrate that CroCo achieves superior bag classification and instance classification performance compared to other comparative methods when limited WSIs with bag labels are available. To the best of our knowledge, this paper presents for the first time the WSWC problem and gives a successful resolution.
SP${ }^3$ : Superpixel-propagated pseudo-label learning for weakly semi-supervised medical image segmentation
Nov 18, 2024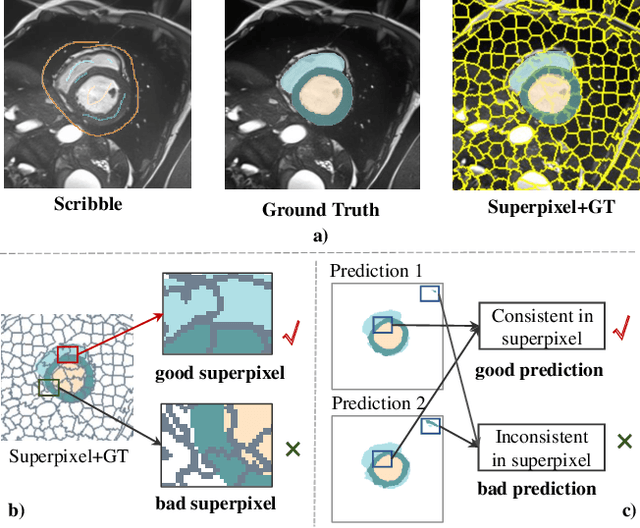



Deep learning-based medical image segmentation helps assist diagnosis and accelerate the treatment process while the model training usually requires large-scale dense annotation datasets. Weakly semi-supervised medical image segmentation is an essential application because it only requires a small amount of scribbles and a large number of unlabeled data to train the model, which greatly reduces the clinician's effort to fully annotate images. To handle the inadequate supervisory information challenge in weakly semi-supervised segmentation (WSSS), a SuperPixel-Propagated Pseudo-label (SP${}^3$) learning method is proposed, using the structural information contained in superpixel for supplemental information. Specifically, the annotation of scribbles is propagated to superpixels and thus obtains a dense annotation for supervised training. Since the quality of pseudo-labels is limited by the low-quality annotation, the beneficial superpixels selected by dynamic thresholding are used to refine pseudo-labels. Furthermore, aiming to alleviate the negative impact of noise in pseudo-label, superpixel-level uncertainty is incorporated to guide the pseudo-label supervision for stable learning. Our method achieves state-of-the-art performance on both tumor and organ segmentation datasets under the WSSS setting, using only 3\% of the annotation workload compared to fully supervised methods and attaining approximately 80\% Dice score. Additionally, our method outperforms eight weakly and semi-supervised methods under both weakly supervised and semi-supervised settings. Results of extensive experiments validate the effectiveness and annotation efficiency of our weakly semi-supervised segmentation, which can assist clinicians in achieving automated segmentation for organs or tumors quickly and ultimately benefit patients.
Local Implicit Wavelet Transformer for Arbitrary-Scale Super-Resolution
Nov 10, 2024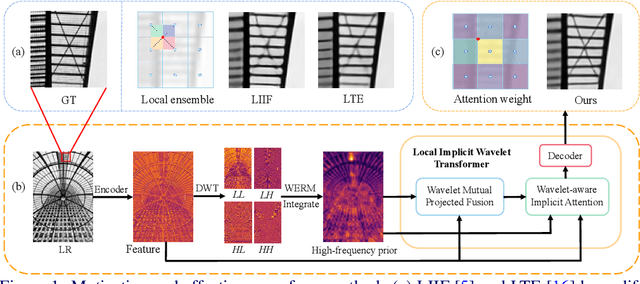
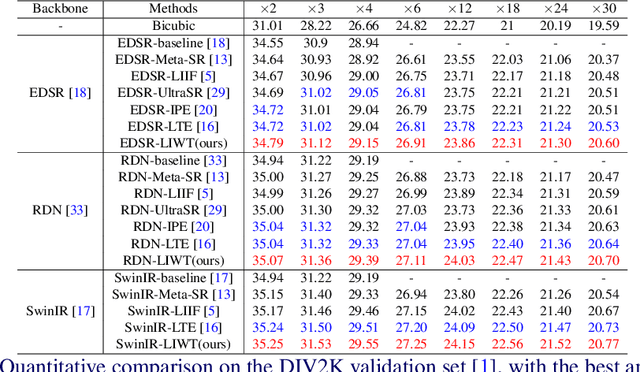


Implicit neural representations have recently demonstrated promising potential in arbitrary-scale Super-Resolution (SR) of images. Most existing methods predict the pixel in the SR image based on the queried coordinate and ensemble nearby features, overlooking the importance of incorporating high-frequency prior information in images, which results in limited performance in reconstructing high-frequency texture details in images. To address this issue, we propose the Local Implicit Wavelet Transformer (LIWT) to enhance the restoration of high-frequency texture details. Specifically, we decompose the features extracted by an encoder into four sub-bands containing different frequency information using Discrete Wavelet Transform (DWT). We then introduce the Wavelet Enhanced Residual Module (WERM) to transform these four sub-bands into high-frequency priors, followed by utilizing the Wavelet Mutual Projected Fusion (WMPF) and the Wavelet-aware Implicit Attention (WIA) to fully exploit the high-frequency prior information for recovering high-frequency details in images. We conducted extensive experiments on benchmark datasets to validate the effectiveness of LIWT. Both qualitative and quantitative results demonstrate that LIWT achieves promising performance in arbitrary-scale SR tasks, outperforming other state-of-the-art methods. The code is available at https://github.com/dmhdmhdmh/LIWT.
Reducing Domain Gap in Frequency and Spatial domain for Cross-modality Domain Adaptation on Medical Image Segmentation
Nov 28, 2022Unsupervised domain adaptation (UDA) aims to learn a model trained on source domain and performs well on unlabeled target domain. In medical image segmentation field, most existing UDA methods depend on adversarial learning to address the domain gap between different image modalities, which is ineffective due to its complicated training process. In this paper, we propose a simple yet effective UDA method based on frequency and spatial domain transfer uner multi-teacher distillation framework. In the frequency domain, we first introduce non-subsampled contourlet transform for identifying domain-invariant and domain-variant frequency components (DIFs and DVFs), and then keep the DIFs unchanged while replacing the DVFs of the source domain images with that of the target domain images to narrow the domain gap. In the spatial domain, we propose a batch momentum update-based histogram matching strategy to reduce the domain-variant image style bias. Experiments on two cross-modality medical image segmentation datasets (cardiac, abdominal) show that our proposed method achieves superior performance compared to state-of-the-art methods.
Robust Point Cloud Registration Framework Based on Deep Graph Matching(TPAMI Version)
Nov 09, 2022



3D point cloud registration is a fundamental problem in computer vision and robotics. Recently, learning-based point cloud registration methods have made great progress. However, these methods are sensitive to outliers, which lead to more incorrect correspondences. In this paper, we propose a novel deep graph matching-based framework for point cloud registration. Specifically, we first transform point clouds into graphs and extract deep features for each point. Then, we develop a module based on deep graph matching to calculate a soft correspondence matrix. By using graph matching, not only the local geometry of each point but also its structure and topology in a larger range are considered in establishing correspondences, so that more correct correspondences are found. We train the network with a loss directly defined on the correspondences, and in the test stage the soft correspondences are transformed into hard one-to-one correspondences so that registration can be performed by a correspondence-based solver. Furthermore, we introduce a transformer-based method to generate edges for graph construction, which further improves the quality of the correspondences. Extensive experiments on object-level and scene-level benchmark datasets show that the proposed method achieves state-of-the-art performance. The code is available at: \href{https://github.com/fukexue/RGM}{https://github.com/fukexue/RGM}.
DGMIL: Distribution Guided Multiple Instance Learning for Whole Slide Image Classification
Jun 17, 2022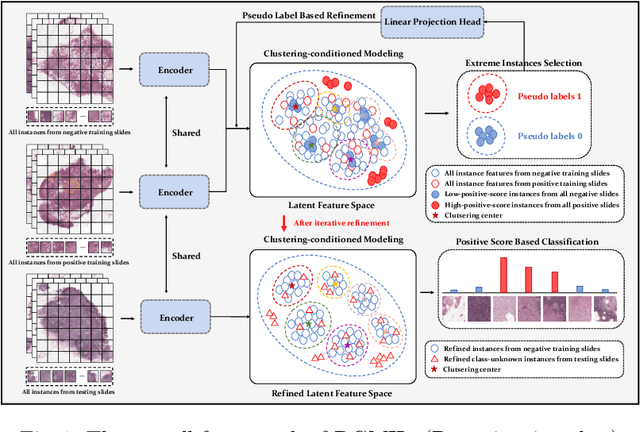
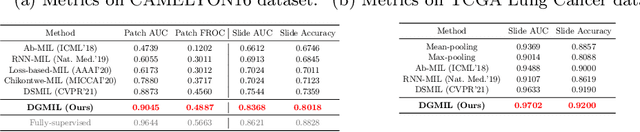

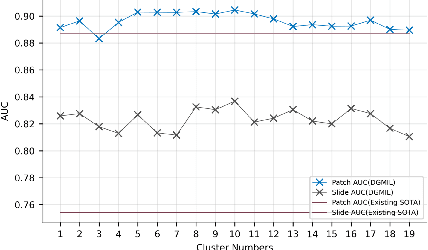
Multiple Instance Learning (MIL) is widely used in analyzing histopathological Whole Slide Images (WSIs). However, existing MIL methods do not explicitly model the data distribution, and instead they only learn a bag-level or instance-level decision boundary discriminatively by training a classifier. In this paper, we propose DGMIL: a feature distribution guided deep MIL framework for WSI classification and positive patch localization. Instead of designing complex discriminative network architectures, we reveal that the inherent feature distribution of histopathological image data can serve as a very effective guide for instance classification. We propose a cluster-conditioned feature distribution modeling method and a pseudo label-based iterative feature space refinement strategy so that in the final feature space the positive and negative instances can be easily separated. Experiments on the CAMELYON16 dataset and the TCGA Lung Cancer dataset show that our method achieves new SOTA for both global classification and positive patch localization tasks.
TransFuse: A Unified Transformer-based Image Fusion Framework using Self-supervised Learning
Jan 19, 2022Image fusion is a technique to integrate information from multiple source images with complementary information to improve the richness of a single image. Due to insufficient task-specific training data and corresponding ground truth, most existing end-to-end image fusion methods easily fall into overfitting or tedious parameter optimization processes. Two-stage methods avoid the need of large amount of task-specific training data by training encoder-decoder network on large natural image datasets and utilizing the extracted features for fusion, but the domain gap between natural images and different fusion tasks results in limited performance. In this study, we design a novel encoder-decoder based image fusion framework and propose a destruction-reconstruction based self-supervised training scheme to encourage the network to learn task-specific features. Specifically, we propose three destruction-reconstruction self-supervised auxiliary tasks for multi-modal image fusion, multi-exposure image fusion and multi-focus image fusion based on pixel intensity non-linear transformation, brightness transformation and noise transformation, respectively. In order to encourage different fusion tasks to promote each other and increase the generalizability of the trained network, we integrate the three self-supervised auxiliary tasks by randomly choosing one of them to destroy a natural image in model training. In addition, we design a new encoder that combines CNN and Transformer for feature extraction, so that the trained model can exploit both local and global information. Extensive experiments on multi-modal image fusion, multi-exposure image fusion and multi-focus image fusion tasks demonstrate that our proposed method achieves the state-of-the-art performance in both subjective and objective evaluations. The code will be publicly available soon.
TransMEF: A Transformer-Based Multi-Exposure Image Fusion Framework using Self-Supervised Multi-Task Learning
Dec 15, 2021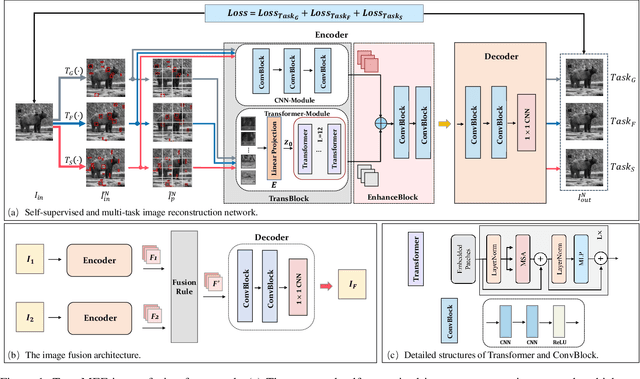
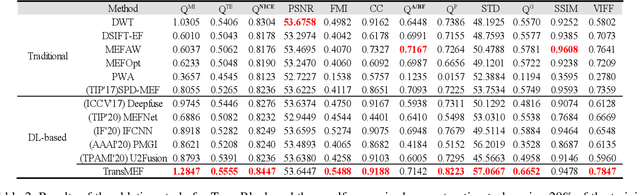


In this paper, we propose TransMEF, a transformer-based multi-exposure image fusion framework that uses self-supervised multi-task learning. The framework is based on an encoder-decoder network, which can be trained on large natural image datasets and does not require ground truth fusion images. We design three self-supervised reconstruction tasks according to the characteristics of multi-exposure images and conduct these tasks simultaneously using multi-task learning; through this process, the network can learn the characteristics of multi-exposure images and extract more generalized features. In addition, to compensate for the defect in establishing long-range dependencies in CNN-based architectures, we design an encoder that combines a CNN module with a transformer module. This combination enables the network to focus on both local and global information. We evaluated our method and compared it to 11 competitive traditional and deep learning-based methods on the latest released multi-exposure image fusion benchmark dataset, and our method achieved the best performance in both subjective and objective evaluations.
A Learnable Self-supervised Task for Unsupervised Domain Adaptation on Point Clouds
Apr 12, 2021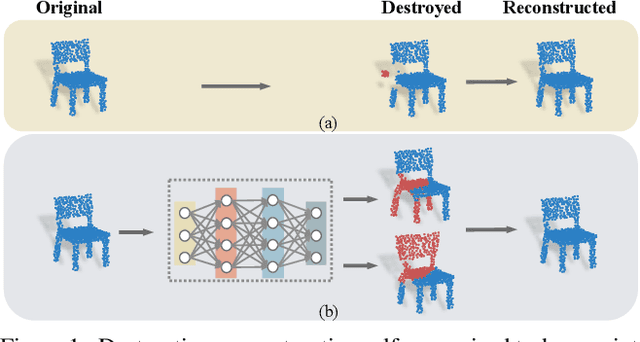
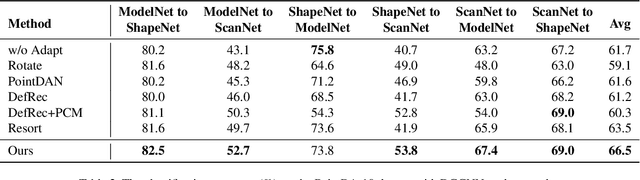
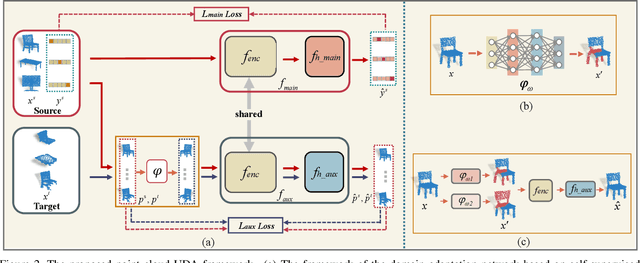
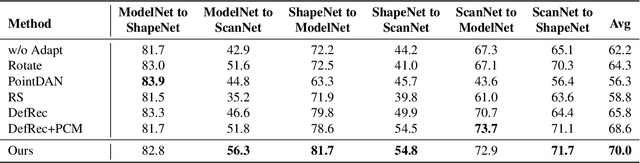
Deep neural networks have achieved promising performance in supervised point cloud applications, but manual annotation is extremely expensive and time-consuming in supervised learning schemes. Unsupervised domain adaptation (UDA) addresses this problem by training a model with only labeled data in the source domain but making the model generalize well in the target domain. Existing studies show that self-supervised learning using both source and target domain data can help improve the adaptability of trained models, but they all rely on hand-crafted designs of the self-supervised tasks. In this paper, we propose a learnable self-supervised task and integrate it into a self-supervision-based point cloud UDA architecture. Specifically, we propose a learnable nonlinear transformation that transforms a part of a point cloud to generate abundant and complicated point clouds while retaining the original semantic information, and the proposed self-supervised task is to reconstruct the original point cloud from the transformed ones. In the UDA architecture, an encoder is shared between the networks for the self-supervised task and the main task of point cloud classification or segmentation, so that the encoder can be trained to extract features suitable for both the source and the target domain data. Experiments on PointDA-10 and PointSegDA datasets show that the proposed method achieves new state-of-the-art performance on both classification and segmentation tasks of point cloud UDA. Code will be made publicly available.