 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQMe14S, A Comprehensive and Efficient Spectral Dataset for Small Organic Molecules
Jan 31, 2025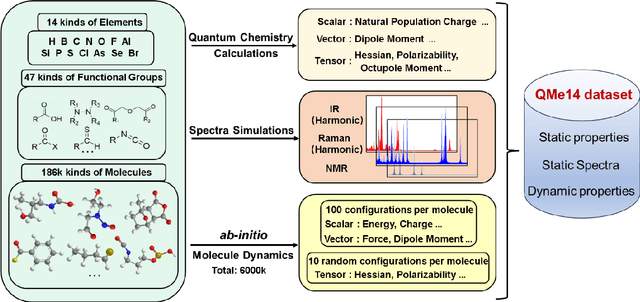
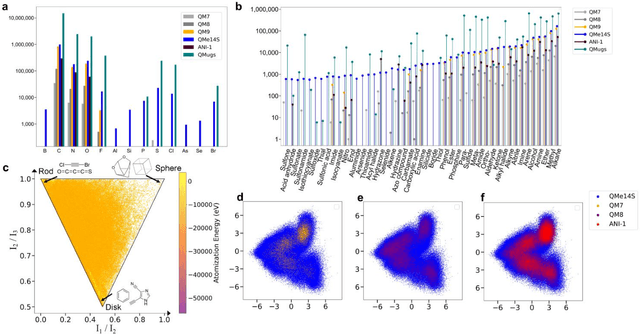
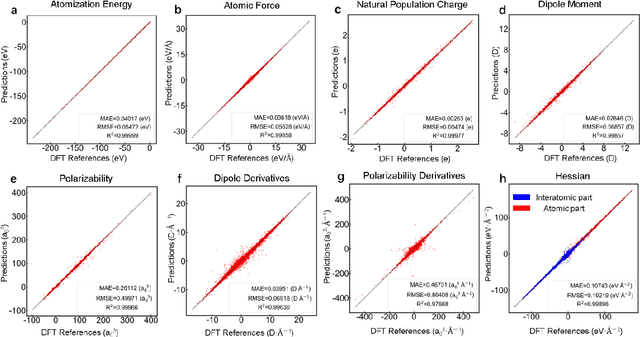

Developing machine learning protocols for molecular simulations requires comprehensive and efficient datasets. Here we introduce the QMe14S dataset, comprising 186,102 small organic molecules featuring 14 elements (H, B, C, N, O, F, Al, Si, P, S, Cl, As, Se, Br) and 47 functional groups. Using density functional theory at the B3LYP/TZVP level, we optimized the geometries and calculated properties including energy, atomic charge, atomic force, dipole moment, quadrupole moment, polarizability, octupole moment, first hyperpolarizability, and Hessian. At the same level, we obtained the harmonic IR, Raman and NMR spectra. Furthermore, we conducted ab initio molecular dynamics simulations to generate dynamic configurations and extract nonequilibrium properties, including energy, forces, and Hessians. By leveraging our E(3)-equivariant message-passing neural network (DetaNet), we demonstrated that models trained on QMe14S outperform those trained on the previously developed QM9S dataset in simulating molecular spectra. The QMe14S dataset thus serves as a comprehensive benchmark for molecular simulations, offering valuable insights into structure-property relationships.
Rethinking Multiple Instance Learning: Developing an Instance-Level Classifier via Weakly-Supervised Self-Training
Aug 09, 2024Multiple instance learning (MIL) problem is currently solved from either bag-classification or instance-classification perspective, both of which ignore important information contained in some instances and result in limited performance. For example, existing methods often face difficulty in learning hard positive instances. In this paper, we formulate MIL as a semi-supervised instance classification problem, so that all the labeled and unlabeled instances can be fully utilized to train a better classifier. The difficulty in this formulation is that all the labeled instances are negative in MIL, and traditional self-training techniques used in semi-supervised learning tend to degenerate in generating pseudo labels for the unlabeled instances in this scenario. To resolve this problem, we propose a weakly-supervised self-training method, in which we utilize the positive bag labels to construct a global constraint and a local constraint on the pseudo labels to prevent them from degenerating and force the classifier to learn hard positive instances. It is worth noting that easy positive instances are instances are far from the decision boundary in the classification process, while hard positive instances are those close to the decision boundary. Through iterative optimization, the pseudo labels can gradually approach the true labels. Extensive experiments on two MNIST synthetic datasets, five traditional MIL benchmark datasets and two histopathology whole slide image datasets show that our method achieved new SOTA performance on all of them. The code will be publicly available.
PointMBF: A Multi-scale Bidirectional Fusion Network for Unsupervised RGB-D Point Cloud Registration
Aug 09, 2023Point cloud registration is a task to estimate the rigid transformation between two unaligned scans, which plays an important role in many computer vision applications. Previous learning-based works commonly focus on supervised registration, which have limitations in practice. Recently, with the advance of inexpensive RGB-D sensors, several learning-based works utilize RGB-D data to achieve unsupervised registration. However, most of existing unsupervised methods follow a cascaded design or fuse RGB-D data in a unidirectional manner, which do not fully exploit the complementary information in the RGB-D data. To leverage the complementary information more effectively, we propose a network implementing multi-scale bidirectional fusion between RGB images and point clouds generated from depth images. By bidirectionally fusing visual and geometric features in multi-scales, more distinctive deep features for correspondence estimation can be obtained, making our registration more accurate. Extensive experiments on ScanNet and 3DMatch demonstrate that our method achieves new state-of-the-art performance. Code will be released at https://github.com/phdymz/PointMBF
Boosting 3D Point Cloud Registration by Transferring Multi-modality Knowledge
Feb 10, 2023The recent multi-modality models have achieved great performance in many vision tasks because the extracted features contain the multi-modality knowledge. However, most of the current registration descriptors have only concentrated on local geometric structures. This paper proposes a method to boost point cloud registration accuracy by transferring the multi-modality knowledge of pre-trained multi-modality model to a new descriptor neural network. Different to the previous multi-modality methods that requires both modalities, the proposed method only requires point clouds during inference. Specifically, we propose an ensemble descriptor neural network combining pre-trained sparse convolution branch and a new point-based convolution branch. By fine-tuning on a single modality data, the proposed method achieves new state-of-the-art results on 3DMatch and competitive accuracy on 3DLoMatch and KITTI.
Boosting Point-BERT by Multi-choice Tokens
Aug 15, 2022
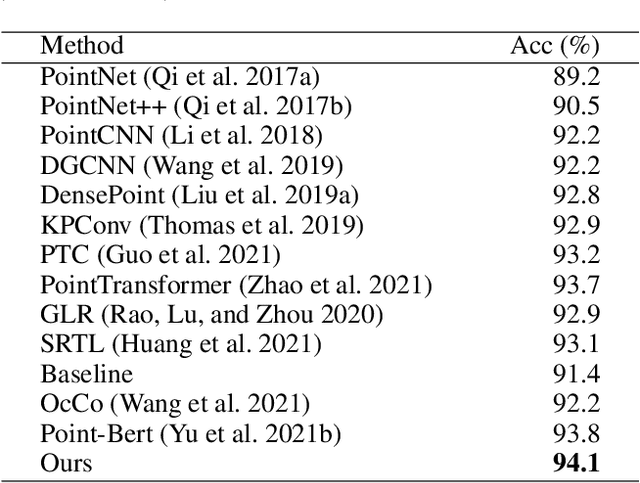
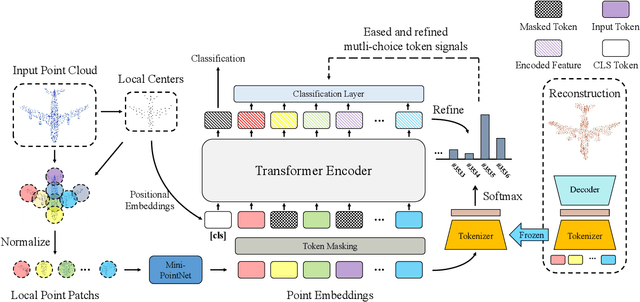
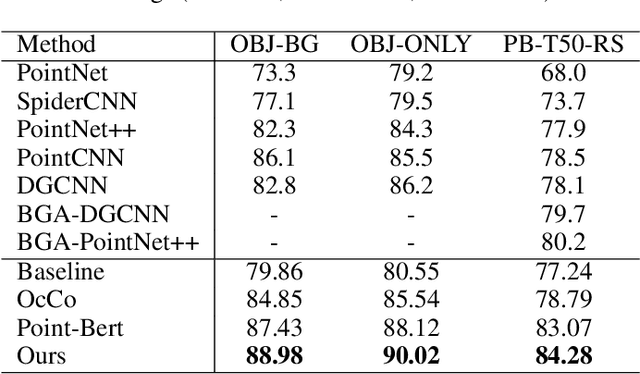
Masked language modeling (MLM) has become one of the most successful self-supervised pre-training task. Inspired by its success, Point-BERT, as a pioneer work in point cloud, proposed masked point modeling (MPM) to pre-train point transformer on large scale unanotated dataset. Despite its great performance, we find the inherent difference between language and point cloud tends to cause ambiguous tokenization for point cloud. For point cloud, there doesn't exist a gold standard for point cloud tokenization. Point-BERT use a discrete Variational AutoEncoder (dVAE) as tokenizer, but it might generate different token ids for semantically-similar patches and generate the same token ids for semantically-dissimilar patches. To tackle above problem, we propose our McP-BERT, a pre-training framework with multi-choice tokens. Specifically, we ease the previous single-choice constraint on patch token ids in Point-BERT, and provide multi-choice token ids for each patch as supervision. Moreover, we utilitze the high-level semantics learned by transformer to further refine our supervision signals. Extensive experiments on point cloud classification, few-shot classification and part segmentation tasks demonstrate the superiority of our method, e.g., the pre-trained transformer achieves 94.1% accuracy on ModelNet40, 84.28% accuracy on the hardest setting of ScanObjectNN and new state-of-the-art performance on few-shot learning. We also demonstrate that our method not only improves the performance of Point-BERT on all downstream tasks, but also incurs almost no extra computational overhead. The code will be released in https://github.com/fukexue/McP-BERT.