 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Extraction and Distillation from Large-Scale Image-Text Colonoscopy Records Leveraging Large Language and Vision Models
Paper and Code
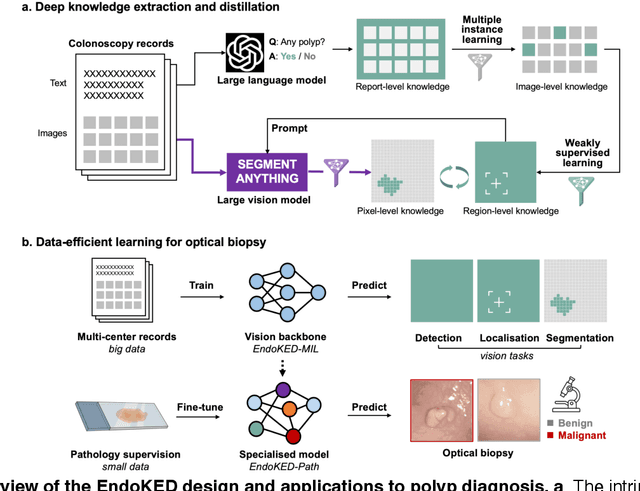
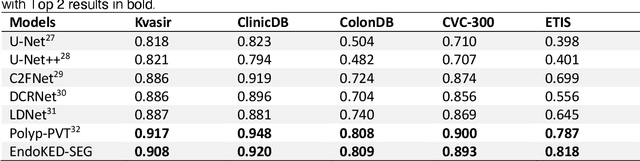
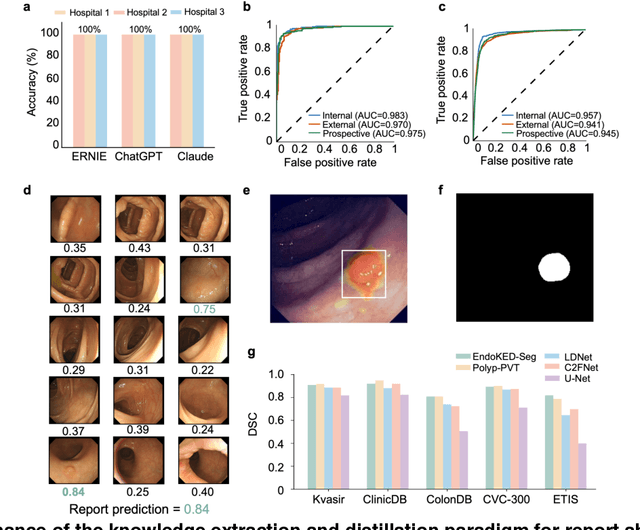
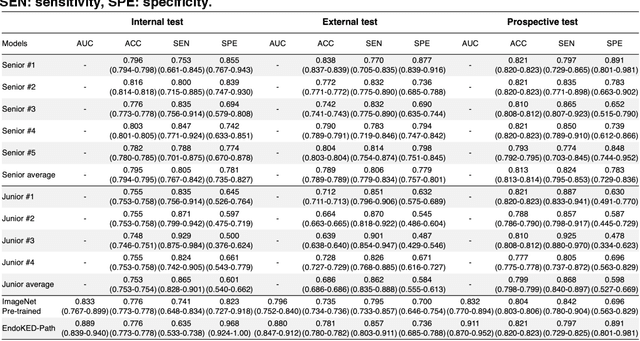
The development of artificial intelligence systems for colonoscopy analysis often necessitates expert-annotated image datasets. However, limitations in dataset size and diversity impede model performance and generalisation. Image-text colonoscopy records from routine clinical practice, comprising millions of images and text reports, serve as a valuable data source, though annotating them is labour-intensive. Here we leverage recent advancements in large language and vision models and propose EndoKED, a data mining paradigm for deep knowledge extraction and distillation. EndoKED automates the transformation of raw colonoscopy records into image datasets with pixel-level annotation. We validate EndoKED using multi-centre datasets of raw colonoscopy records (~1 million images), demonstrating its superior performance in training polyp detection and segmentation models. Furthermore, the EndoKED pre-trained vision backbone enables data-efficient and generalisable learning for optical biopsy, achieving expert-level performance in both retrospective and prospective validation.