 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Text-Video Retrieval with Frozen Image Encoders
Paper and Code
Jul 14, 2023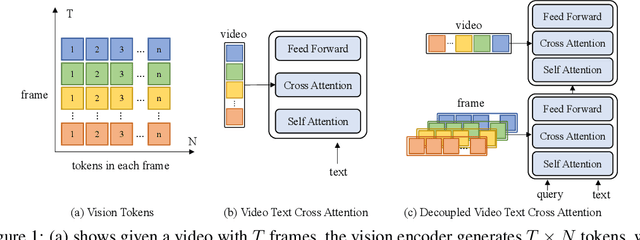
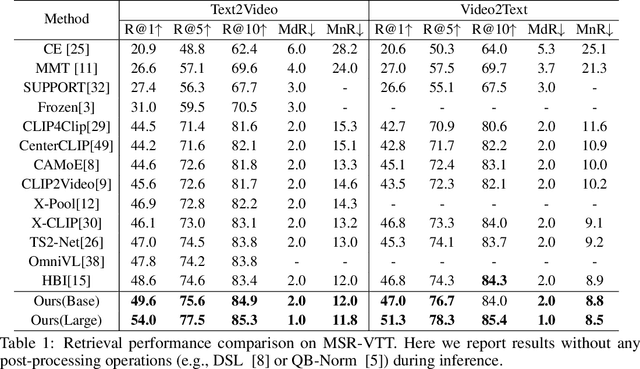
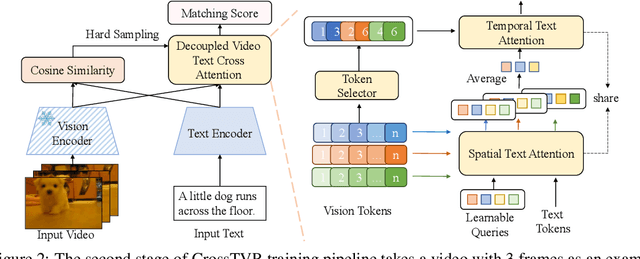

State-of-the-art text-video retrieval (TVR) methods typically utilize CLIP and cosine similarity for efficient retrieval. Meanwhile, cross attention methods, which employ a transformer decoder to compute attention between each text query and all frames in a video, offer a more comprehensive interaction between text and videos. However, these methods lack important fine-grained spatial information as they directly compute attention between text and video-level tokens. To address this issue, we propose CrossTVR, a two-stage text-video retrieval architecture. In the first stage, we leverage existing TVR methods with cosine similarity network for efficient text/video candidate selection. In the second stage, we propose a novel decoupled video text cross attention module to capture fine-grained multimodal information in spatial and temporal dimensions. Additionally, we employ the frozen CLIP model strategy in fine-grained retrieval, enabling scalability to larger pre-trained vision models like ViT-G, resulting in improved retrieval performance. Experiments on text video retrieval datasets demonstrate the effectiveness and scalability of our proposed CrossTVR compared to state-of-the-art approaches.