 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAFaRe: Learning Robust and Accurate Non-parametric 3D Face Reconstruction from Pseudo 2D&3D Pairs
Feb 10, 2023



We propose a robust and accurate non-parametric method for single-view 3D face reconstruction (SVFR). While tremendous efforts have been devoted to parametric SVFR, a visible gap still lies between the result 3D shape and the ground truth. We believe there are two major obstacles: 1) the representation of the parametric model is limited to a certain face database; 2) 2D images and 3D shapes in the fitted datasets are distinctly misaligned. To resolve these issues, a large-scale pseudo 2D\&3D dataset is created by first rendering the detailed 3D faces, then swapping the face in the wild images with the rendered face. These pseudo 2D&3D pairs are created from publicly available datasets which eliminate the gaps between 2D and 3D data while covering diverse appearances, poses, scenes, and illumination. We further propose a non-parametric scheme to learn a well-generalized SVFR model from the created dataset, and the proposed hierarchical signed distance function turns out to be effective in predicting middle-scale and small-scale 3D facial geometry. Our model outperforms previous methods on FaceScape-wild/lab and MICC benchmarks and is well generalized to various appearances, poses, expressions, and in-the-wild environments. The code is released at http://github.com/zhuhao-nju/rafare .
FaceScape: 3D Facial Dataset and Benchmark for Single-View 3D Face Reconstruction
Nov 01, 2021
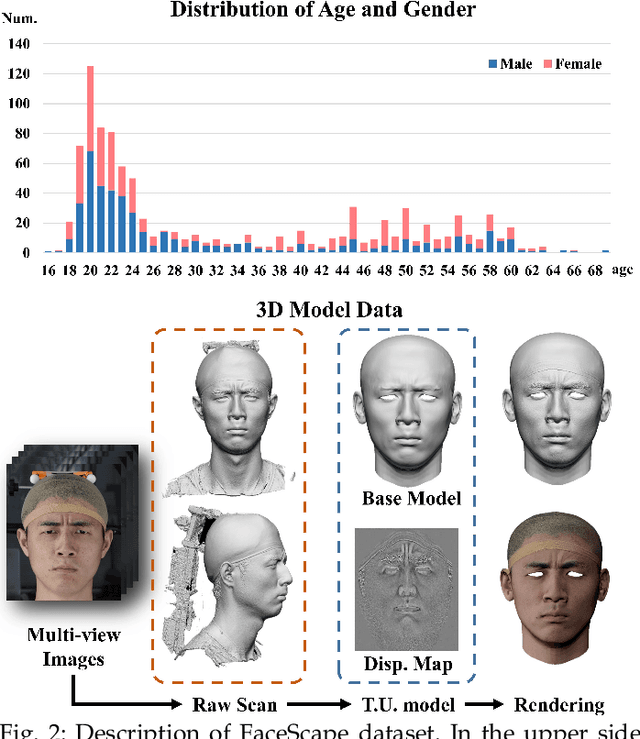
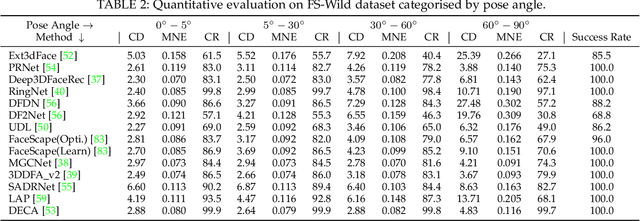
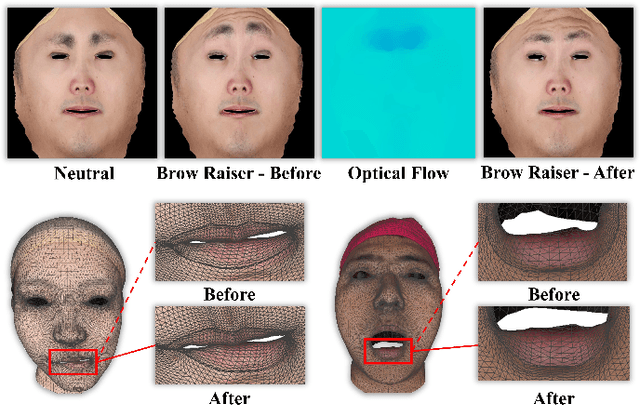
In this paper, we present a large-scale detailed 3D face dataset, FaceScape, and the corresponding benchmark to evaluate single-view facial 3D reconstruction. By training on FaceScape data, a novel algorithm is proposed to predict elaborate riggable 3D face models from a single image input. FaceScape dataset provides 18,760 textured 3D faces, captured from 938 subjects and each with 20 specific expressions. The 3D models contain the pore-level facial geometry that is also processed to be topologically uniformed. These fine 3D facial models can be represented as a 3D morphable model for rough shapes and displacement maps for detailed geometry. Taking advantage of the large-scale and high-accuracy dataset, a novel algorithm is further proposed to learn the expression-specific dynamic details using a deep neural network. The learned relationship serves as the foundation of our 3D face prediction system from a single image input. Different than the previous methods, our predicted 3D models are riggable with highly detailed geometry under different expressions. We also use FaceScape data to generate the in-the-wild and in-the-lab benchmark to evaluate recent methods of single-view face reconstruction. The accuracy is reported and analyzed on the dimensions of camera pose and focal length, which provides a faithful and comprehensive evaluation and reveals new challenges. The unprecedented dataset, benchmark, and code have been released to the public for research purpose.