 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeighborhood Averaging for Improving Outlier Detectors
Mar 17, 2023

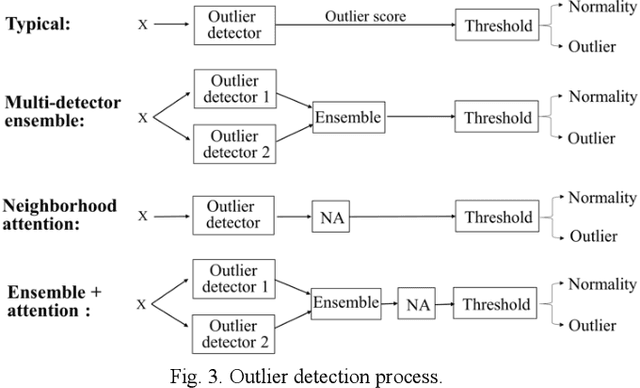

We hypothesize that similar objects should have similar outlier scores. To our knowledge, all existing outlier detectors calculate the outlier score for each object independently regardless of the outlier scores of the other objects. Therefore, they do not guarantee that similar objects have similar outlier scores. To verify our proposed hypothesis, we propose an outlier score post-processing technique for outlier detectors, called neighborhood averaging(NA), which pays attention to objects and their neighbors and guarantees them to have more similar outlier scores than their original scores. Given an object and its outlier score from any outlier detector, NA modifies its outlier score by combining it with its k nearest neighbors' scores. We demonstrate the effectivity of NA by using the well-known k-nearest neighbors (k-NN). Experimental results show that NA improves all 10 tested baseline detectors by 13% (from 0.70 to 0.79 AUC) on average evaluated on nine real-world datasets. Moreover, even outlier detectors that are already based on k-NN are also improved. The experiments also show that in some applications, the choice of detector is no more significant when detectors are jointly used with NA, which may pose a challenge to the generally considered idea that the data model is the most important factor. We open our code on www.outlierNet.com for reproducibility.