 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualVC: Dual-mode Voice Conversion using Intra-model Knowledge Distillation and Hybrid Predictive Coding
Paper and Code
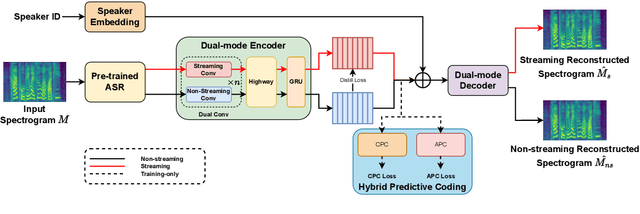
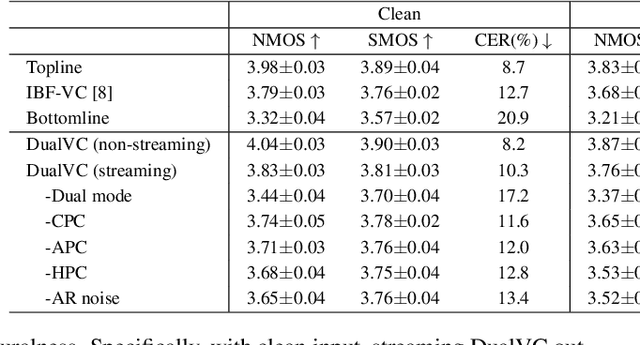
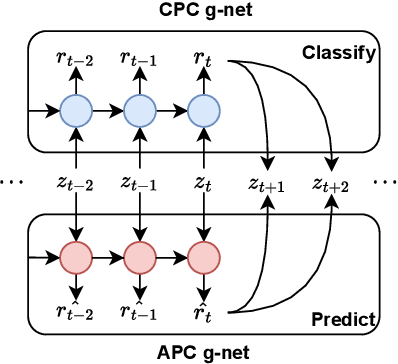
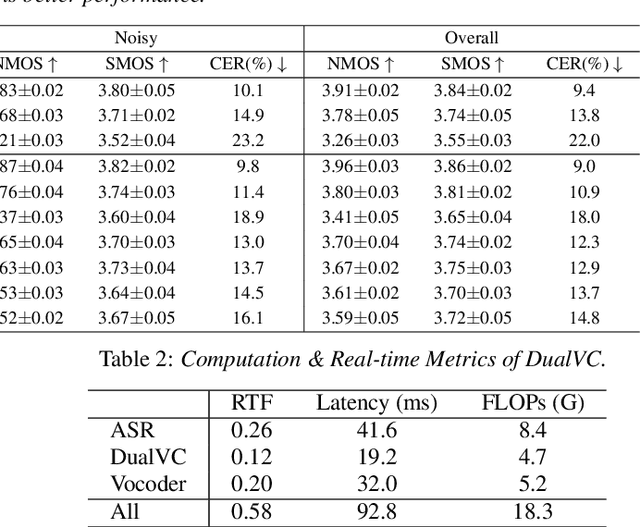
Voice conversion is an increasingly popular technology, and the growing number of real-time applications requires models with streaming conversion capabilities. Unlike typical (non-streaming) voice conversion, which can leverage the entire utterance as full context, streaming voice conversion faces significant challenges due to the missing future information, resulting in degraded intelligibility, speaker similarity, and sound quality. To address this challenge, we propose DualVC, a dual-mode neural voice conversion approach that supports both streaming and non-streaming modes using jointly trained separate network parameters. Furthermore, we propose intra-model knowledge distillation and hybrid predictive coding (HPC) to enhance the performance of streaming conversion. Additionally, we incorporate data augmentation to train a noise-robust autoregressive decoder, improving the model's performance on long-form speech conversion. Experimental results demonstrate that the proposed model outperforms the baseline models in the context of streaming voice conversion, while maintaining comparable performance to the non-streaming topline system that leverages the complete context, albeit with a latency of only 252.8 ms.