 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualVC 3: Leveraging Language Model Generated Pseudo Context for End-to-end Low Latency Streaming Voice Conversion
Paper and Code
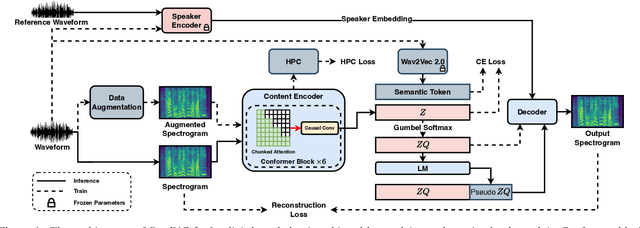
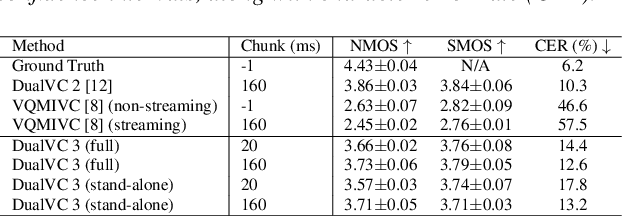
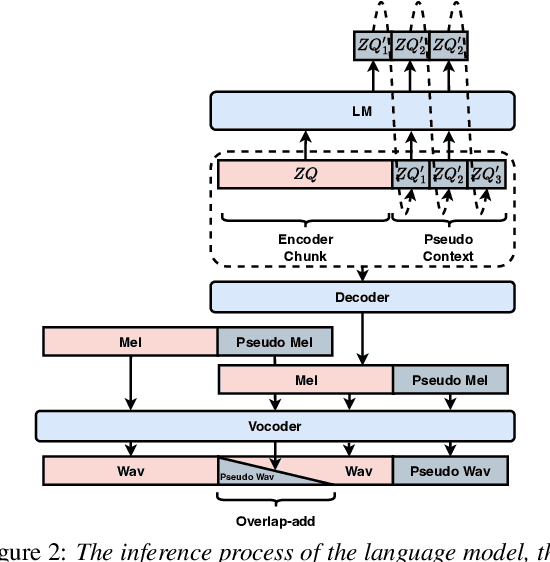
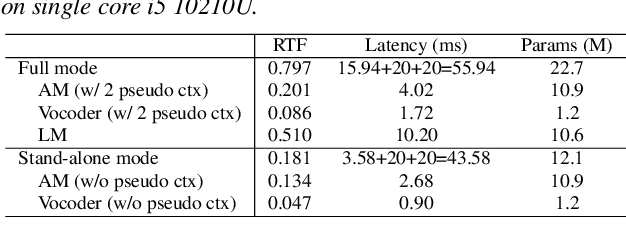
Streaming voice conversion has become increasingly popular for its potential in real-time applications. The recently proposed DualVC 2 has achieved robust and high-quality streaming voice conversion with a latency of about 180ms. Nonetheless, the recognition-synthesis framework hinders end-to-end optimization, and the instability of automatic speech recognition (ASR) model with short chunks makes it challenging to further reduce latency. To address these issues, we propose an end-to-end model, DualVC 3. With speaker-independent semantic tokens to guide the training of the content encoder, the dependency on ASR is removed and the model can operate under extremely small chunks, with cascading errors eliminated. A language model is trained on the content encoder output to produce pseudo context by iteratively predicting future frames, providing more contextual information for the decoder to improve conversion quality. Experimental results demonstrate that DualVC 3 achieves comparable performance to DualVC 2 in subjective and objective metrics, with a latency of only 50 ms.