 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualVC 2: Dynamic Masked Convolution for Unified Streaming and Non-Streaming Voice Conversion
Paper and Code
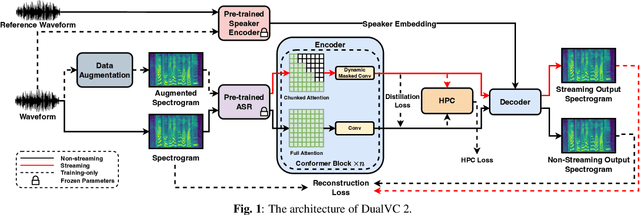
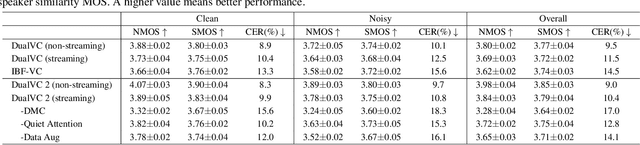
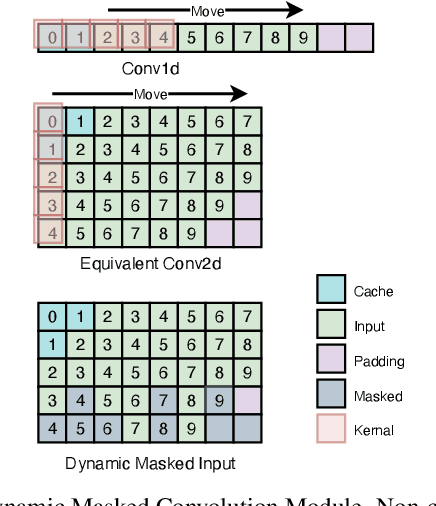
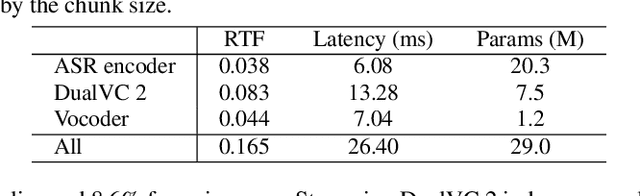
Voice conversion is becoming increasingly popular, and a growing number of application scenarios require models with streaming inference capabilities. The recently proposed DualVC attempts to achieve this objective through streaming model architecture design and intra-model knowledge distillation along with hybrid predictive coding to compensate for the lack of future information. However, DualVC encounters several problems that limit its performance. First, the autoregressive decoder has error accumulation in its nature and limits the inference speed as well. Second, the causal convolution enables streaming capability but cannot sufficiently use future information within chunks. Third, the model is unable to effectively address the noise in the unvoiced segments, lowering the sound quality. In this paper, we propose DualVC 2 to address these issues. Specifically, the model backbone is migrated to a Conformer-based architecture, empowering parallel inference. Causal convolution is replaced by non-causal convolution with dynamic chunk mask to make better use of within-chunk future information. Also, quiet attention is introduced to enhance the model's noise robustness. Experiments show that DualVC 2 outperforms DualVC and other baseline systems in both subjective and objective metrics, with only 186.4 ms latency. Our audio samples are made publicly available.