 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyoneNet: Synchronized Speech and Talking Head Generation for Arbitrary Person
Paper and Code
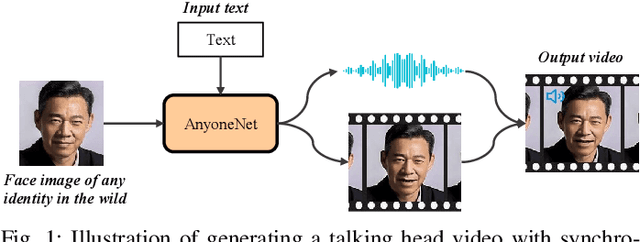
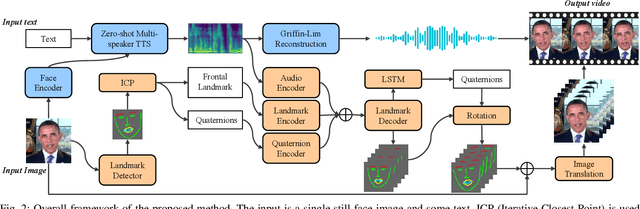
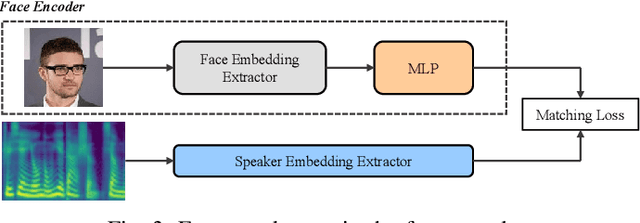

Automatically generating videos in which synthesized speech is synchronized with lip movements in a talking head has great potential in many human-computer interaction scenarios. In this paper, we present an automatic method to generate synchronized speech and talking-head videos on the basis of text and a single face image of an arbitrary person as input. In contrast to previous text-driven talking head generation methods, which can only synthesize the voice of a specific person, the proposed method is capable of synthesizing speech for any person that is inaccessible in the training stage. Specifically, the proposed method decomposes the generation of synchronized speech and talking head videos into two stages, i.e., a text-to-speech (TTS) stage and a speech-driven talking head generation stage. The proposed TTS module is a face-conditioned multi-speaker TTS model that gets the speaker identity information from face images instead of speech, which allows us to synthesize a personalized voice on the basis of the input face image. To generate the talking head videos from the face images, a facial landmark-based method that can predict both lip movements and head rotations is proposed. Extensive experiments demonstrate that the proposed method is able to generate synchronized speech and talking head videos for arbitrary persons and non-persons. Synthesized speech shows consistency with the given face regarding to the synthesized voice's timbre and one's appearance in the image, and the proposed landmark-based talking head method outperforms the state-of-the-art landmark-based method on generating natural talking head videos.