 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Domain-Invariant Temporal Dynamics for Few-Shot Action Recognition
Feb 20, 2024
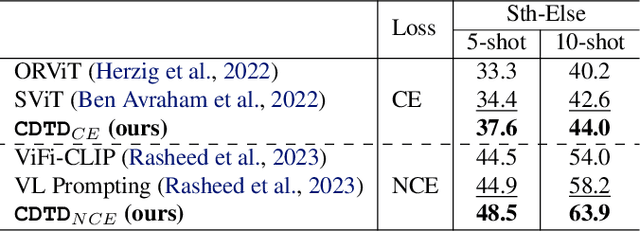
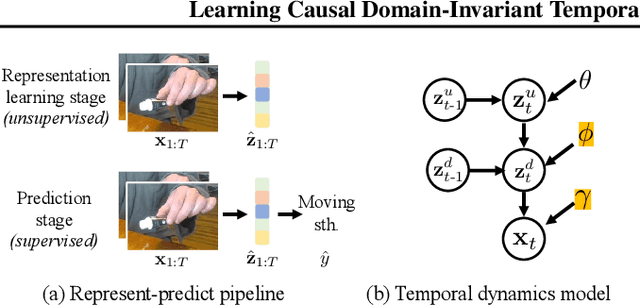

Few-shot action recognition aims at quickly adapting a pre-trained model to the novel data with a distribution shift using only a limited number of samples. Key challenges include how to identify and leverage the transferable knowledge learned by the pre-trained model. Our central hypothesis is that temporal invariance in the dynamic system between latent variables lends itself to transferability (domain-invariance). We therefore propose DITeD, or Domain-Invariant Temporal Dynamics for knowledge transfer. To detect the temporal invariance part, we propose a generative framework with a two-stage training strategy during pre-training. Specifically, we explicitly model invariant dynamics including temporal dynamic generation and transitions, and the variant visual and domain encoders. Then we pre-train the model with the self-supervised signals to learn the representation. After that, we fix the whole representation model and tune the classifier. During adaptation, we fix the transferable temporal dynamics and update the image encoder. The efficacy of our approach is revealed by the superior accuracy of DITeD over leading alternatives across standard few-shot action recognition datasets. Moreover, we validate that the learned temporal dynamic transition and temporal dynamic generation modules possess transferable qualities.