 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLalaEval: A Holistic Human Evaluation Framework for Domain-Specific Large Language Models
Paper and Code
Aug 23, 2024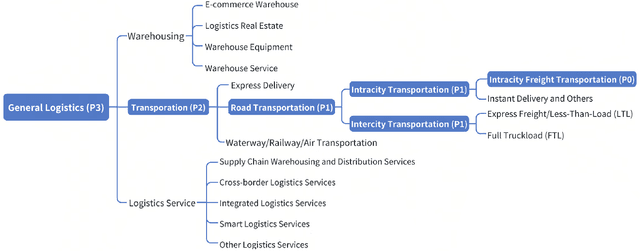


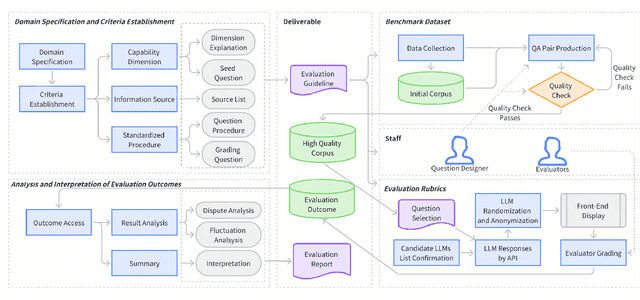
This paper introduces LalaEval, a holistic framework designed for the human evaluation of domain-specific large language models (LLMs). LalaEval proposes a comprehensive suite of end-to-end protocols that cover five main components including domain specification, criteria establishment, benchmark dataset creation, construction of evaluation rubrics, and thorough analysis and interpretation of evaluation outcomes. This initiative aims to fill a crucial research gap by providing a systematic methodology for conducting standardized human evaluations within specific domains, a practice that, despite its widespread application, lacks substantial coverage in the literature and human evaluation are often criticized to be less reliable due to subjective factors, so standardized procedures adapted to the nuanced requirements of specific domains or even individual organizations are in great need. Furthermore, the paper demonstrates the framework's application within the logistics industry, presenting domain-specific evaluation benchmarks, datasets, and a comparative analysis of LLMs for the logistics domain use, highlighting the framework's capacity to elucidate performance differences and guide model selection and development for domain-specific LLMs. Through real-world deployment, the paper underscores the framework's effectiveness in advancing the field of domain-specific LLM evaluation, thereby contributing significantly to the ongoing discussion on LLMs' practical utility and performance in domain-specific applications.