 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrad-ECLIP: Gradient-based Visual and Textual Explanations for CLIP
Feb 26, 2025Significant progress has been achieved on the improvement and downstream usages of the Contrastive Language-Image Pre-training (CLIP) vision-language model, while less attention is paid to the interpretation of CLIP. We propose a Gradient-based visual and textual Explanation method for CLIP (Grad-ECLIP), which interprets the matching result of CLIP for specific input image-text pair. By decomposing the architecture of the encoder and discovering the relationship between the matching similarity and intermediate spatial features, Grad-ECLIP produces effective heat maps that show the influence of image regions or words on the CLIP results. Different from the previous Transformer interpretation methods that focus on the utilization of self-attention maps, which are typically extremely sparse in CLIP, we produce high-quality visual explanations by applying channel and spatial weights on token features. Qualitative and quantitative evaluations verify the effectiveness and superiority of Grad-ECLIP compared with the state-of-the-art methods. Furthermore, a series of analysis are conducted based on our visual and textual explanation results, from which we explore the working mechanism of image-text matching, the strengths and limitations in attribution identification of CLIP, and the relationship between the concreteness/abstractness of a word and its usage in CLIP. Finally, based on the ability of explanation map that indicates text-specific saliency region of input image, we also propose an application with Grad-ECLIP, which is adopted to boost the fine-grained alignment in the CLIP fine-tuning. The code of Grad-ECLIP is available here: https://github.com/Cyang-Zhao/Grad-Eclip.
Human Attention-Guided Explainable Artificial Intelligence for Computer Vision Models
May 05, 2023We examined whether embedding human attention knowledge into saliency-based explainable AI (XAI) methods for computer vision models could enhance their plausibility and faithfulness. We first developed new gradient-based XAI methods for object detection models to generate object-specific explanations by extending the current methods for image classification models. Interestingly, while these gradient-based methods worked well for explaining image classification models, when being used for explaining object detection models, the resulting saliency maps generally had lower faithfulness than human attention maps when performing the same task. We then developed Human Attention-Guided XAI (HAG-XAI) to learn from human attention how to best combine explanatory information from the models to enhance explanation plausibility by using trainable activation functions and smoothing kernels to maximize XAI saliency map's similarity to human attention maps. While for image classification models, HAG-XAI enhanced explanation plausibility at the expense of faithfulness, for object detection models it enhanced plausibility and faithfulness simultaneously and outperformed existing methods. The learned functions were model-specific, well generalizable to other databases.
EMHMM Simulation Study
Oct 17, 2018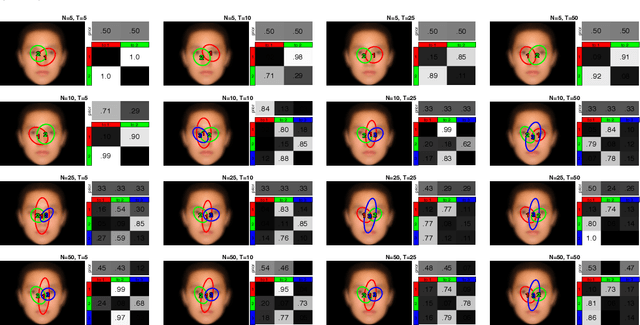
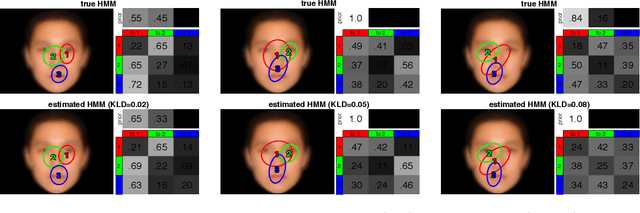


Eye Movement analysis with Hidden Markov Models (EMHMM) is a method for modeling eye fixation sequences using hidden Markov models (HMMs). In this report, we run a simulation study to investigate the estimation error for learning HMMs with variational Bayesian inference, with respect to the number of sequences and the sequence lengths. We also relate the estimation error measured by KL divergence and L1-norm to a corresponding distortion in the ground-truth HMM parameters.