 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Diffusion-based Generation of Adversarial Objects for Real-World Monocular Depth Estimation Attacks
Dec 30, 2025Monocular Depth Estimation (MDE) serves as a core perception module in autonomous driving systems, but it remains highly susceptible to adversarial attacks. Errors in depth estimation may propagate through downstream decision making and influence overall traffic safety. Existing physical attacks primarily rely on texture-based patches, which impose strict placement constraints and exhibit limited realism, thereby reducing their effectiveness in complex driving environments. To overcome these limitations, this work introduces a training-free generative adversarial attack framework that generates naturalistic, scene-consistent adversarial objects via a diffusion-based conditional generation process. The framework incorporates a Salient Region Selection module that identifies regions most influential to MDE and a Jacobian Vector Product Guidance mechanism that steers adversarial gradients toward update directions supported by the pre-trained diffusion model. This formulation enables the generation of physically plausible adversarial objects capable of inducing substantial adversarial depth shifts. Extensive digital and physical experiments demonstrate that our method significantly outperforms existing attacks in effectiveness, stealthiness, and physical deployability, underscoring its strong practical implications for autonomous driving safety assessment.
Reloc-VGGT: Visual Re-localization with Geometry Grounded Transformer
Dec 26, 2025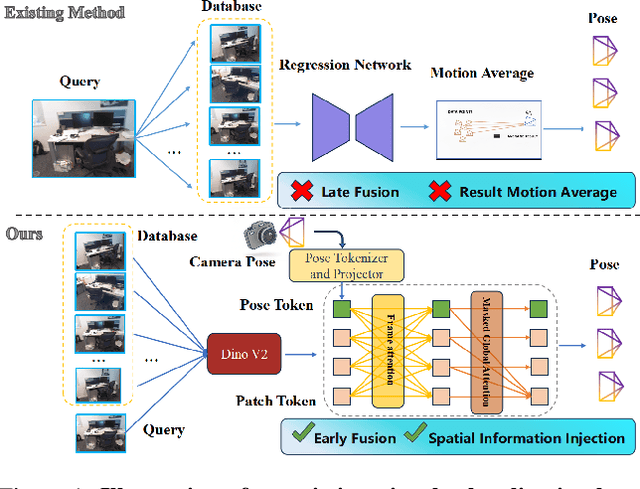
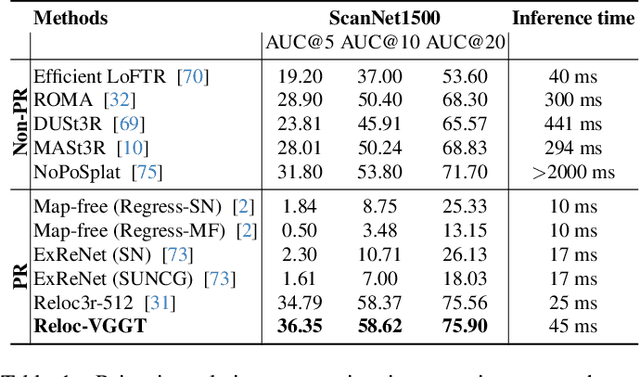
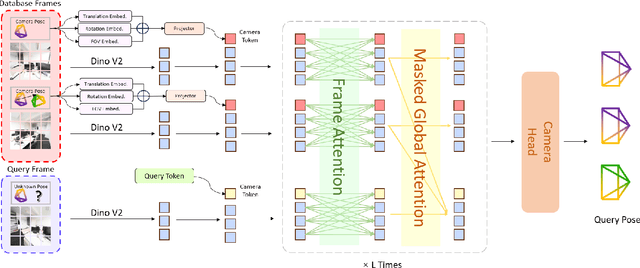
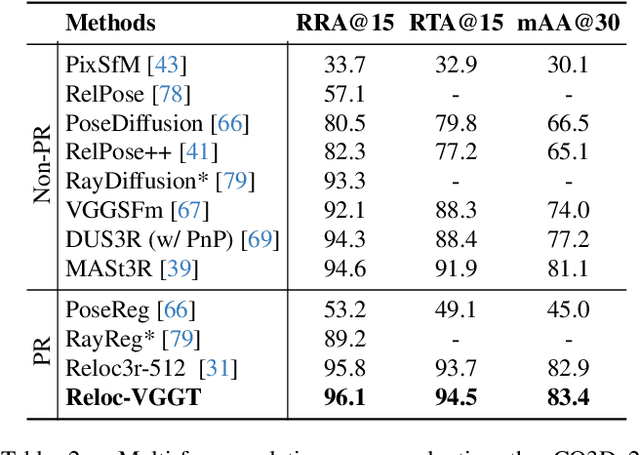
Visual localization has traditionally been formulated as a pair-wise pose regression problem. Existing approaches mainly estimate relative poses between two images and employ a late-fusion strategy to obtain absolute pose estimates. However, the late motion average is often insufficient for effectively integrating spatial information, and its accuracy degrades in complex environments. In this paper, we present the first visual localization framework that performs multi-view spatial integration through an early-fusion mechanism, enabling robust operation in both structured and unstructured environments. Our framework is built upon the VGGT backbone, which encodes multi-view 3D geometry, and we introduce a pose tokenizer and projection module to more effectively exploit spatial relationships from multiple database views. Furthermore, we propose a novel sparse mask attention strategy that reduces computational cost by avoiding the quadratic complexity of global attention, thereby enabling real-time performance at scale. Trained on approximately eight million posed image pairs, Reloc-VGGT demonstrates strong accuracy and remarkable generalization ability. Extensive experiments across diverse public datasets consistently validate the effectiveness and efficiency of our approach, delivering high-quality camera pose estimates in real time while maintaining robustness to unseen environments. Our code and models will be publicly released upon acceptance.https://github.com/dtc111111/Reloc-VGGT.
PLGSLAM: Progressive Neural Scene Represenation with Local to Global Bundle Adjustment
Dec 15, 2023



Neural implicit scene representations have recently shown encouraging results in dense visual SLAM. However, existing methods produce low-quality scene reconstruction and low-accuracy localization performance when scaling up to large indoor scenes and long sequences. These limitations are mainly due to their single, global radiance field with finite capacity, which does not adapt to large scenarios. Their end-to-end pose networks are also not robust enough with the growth of cumulative errors in large scenes. To this end, we present PLGSLAM, a neural visual SLAM system which performs high-fidelity surface reconstruction and robust camera tracking in real time. To handle large-scale indoor scenes, PLGSLAM proposes a progressive scene representation method which dynamically allocates new local scene representation trained with frames within a local sliding window. This allows us to scale up to larger indoor scenes and improves robustness (even under pose drifts). In local scene representation, PLGSLAM utilizes tri-planes for local high-frequency features. We also incorporate multi-layer perceptron (MLP) networks for the low-frequency feature, smoothness, and scene completion in unobserved areas. Moreover, we propose local-to-global bundle adjustment method with a global keyframe database to address the increased pose drifts on long sequences. Experimental results demonstrate that PLGSLAM achieves state-of-the-art scene reconstruction results and tracking performance across various datasets and scenarios (both in small and large-scale indoor environments). The code will be open-sourced upon paper acceptance.