 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Zero-Shot Vision Models by Label-Free Prompt Distribution Learning and Bias Correcting
Paper and Code
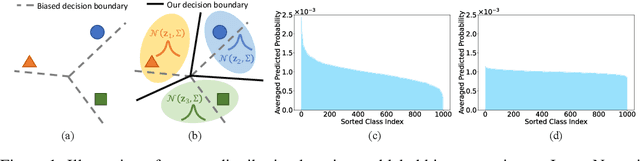

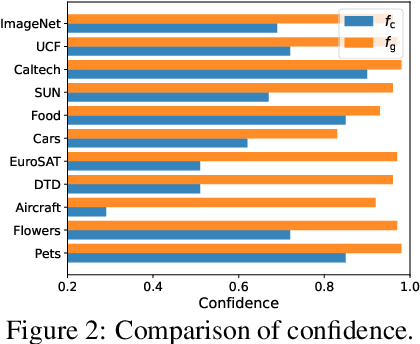

Vision-language models, such as CLIP, have shown impressive generalization capacities when using appropriate text descriptions. While optimizing prompts on downstream labeled data has proven effective in improving performance, these methods entail labor costs for annotations and are limited by their quality. Additionally, since CLIP is pre-trained on highly imbalanced Web-scale data, it suffers from inherent label bias that leads to suboptimal performance. To tackle the above challenges, we propose a label-Free prompt distribution learning and bias correction framework, dubbed as **Frolic**, which boosts zero-shot performance without the need for labeled data. Specifically, our Frolic learns distributions over prompt prototypes to capture diverse visual representations and adaptively fuses these with the original CLIP through confidence matching. This fused model is further enhanced by correcting label bias via a label-free logit adjustment. Notably, our method is not only training-free but also circumvents the necessity for hyper-parameter tuning. Extensive experimental results across 16 datasets demonstrate the efficacy of our approach, particularly outperforming the state-of-the-art by an average of $2.6\%$ on 10 datasets with CLIP ViT-B/16 and achieving an average margin of $1.5\%$ on ImageNet and its five distribution shifts with CLIP ViT-B/16. Codes are available in https://github.com/zhuhsingyuu/Frolic.