 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCONQUER: Contextual Query-aware Ranking for Video Corpus Moment Retrieval
Sep 21, 2021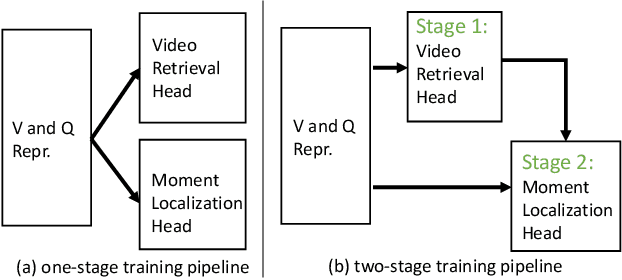

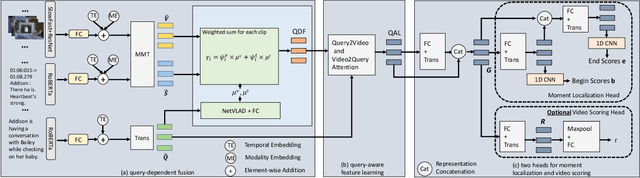

This paper tackles a recently proposed Video Corpus Moment Retrieval task. This task is essential because advanced video retrieval applications should enable users to retrieve a precise moment from a large video corpus. We propose a novel CONtextual QUery-awarE Ranking~(CONQUER) model for effective moment localization and ranking. CONQUER explores query context for multi-modal fusion and representation learning in two different steps. The first step derives fusion weights for the adaptive combination of multi-modal video content. The second step performs bi-directional attention to tightly couple video and query as a single joint representation for moment localization. As query context is fully engaged in video representation learning, from feature fusion to transformation, the resulting feature is user-centered and has a larger capacity in capturing multi-modal signals specific to query. We conduct studies on two datasets, TVR for closed-world TV episodes and DiDeMo for open-world user-generated videos, to investigate the potential advantages of fusing video and query online as a joint representation for moment retrieval.