 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRUST-FS: Tensorized Reliable Unsupervised Multi-View Feature Selection for Incomplete Data
Sep 16, 2025Multi-view unsupervised feature selection (MUFS), which selects informative features from multi-view unlabeled data, has attracted increasing research interest in recent years. Although great efforts have been devoted to MUFS, several challenges remain: 1) existing methods for incomplete multi-view data are limited to handling missing views and are unable to address the more general scenario of missing variables, where some features have missing values in certain views; 2) most methods address incomplete data by first imputing missing values and then performing feature selection, treating these two processes independently and overlooking their interactions; 3) missing data can result in an inaccurate similarity graph, which reduces the performance of feature selection. To solve this dilemma, we propose a novel MUFS method for incomplete multi-view data with missing variables, termed Tensorized Reliable UnSupervised mulTi-view Feature Selection (TRUST-FS). TRUST-FS introduces a new adaptive-weighted CP decomposition that simultaneously performs feature selection, missing-variable imputation, and view weight learning within a unified tensor factorization framework. By utilizing Subjective Logic to acquire trustworthy cross-view similarity information, TRUST-FS facilitates learning a reliable similarity graph, which subsequently guides feature selection and imputation. Comprehensive experimental results demonstrate the effectiveness and superiority of our method over state-of-the-art methods.
CONDEN-FI: Consistency and Diversity Learning-based Multi-View Unsupervised Feature and In-stance Co-Selection
Dec 09, 2024



The objective of multi-view unsupervised feature and instance co-selection is to simultaneously iden-tify the most representative features and samples from multi-view unlabeled data, which aids in mit-igating the curse of dimensionality and reducing instance size to improve the performance of down-stream tasks. However, existing methods treat feature selection and instance selection as two separate processes, failing to leverage the potential interactions between the feature and instance spaces. Addi-tionally, previous co-selection methods for multi-view data require concatenating different views, which overlooks the consistent information among them. In this paper, we propose a CONsistency and DivErsity learNing-based multi-view unsupervised Feature and Instance co-selection (CONDEN-FI) to address the above-mentioned issues. Specifically, CONDEN-FI reconstructs mul-ti-view data from both the sample and feature spaces to learn representations that are consistent across views and specific to each view, enabling the simultaneous selection of the most important features and instances. Moreover, CONDEN-FI adaptively learns a view-consensus similarity graph to help select both dissimilar and similar samples in the reconstructed data space, leading to a more diverse selection of instances. An efficient algorithm is developed to solve the resultant optimization problem, and the comprehensive experimental results on real-world datasets demonstrate that CONDEN-FI is effective compared to state-of-the-art methods.
Adaptive Collaborative Correlation Learning-based Semi-Supervised Multi-Label Feature Selection
Jun 18, 2024Semi-supervised multi-label feature selection has recently been developed to solve the curse of dimensionality problem in high-dimensional multi-label data with certain samples missing labels. Although many efforts have been made, most existing methods use a predefined graph approach to capture the sample similarity or the label correlation. In this manner, the presence of noise and outliers within the original feature space can undermine the reliability of the resulting sample similarity graph. It also fails to precisely depict the label correlation due to the existence of unknown labels. Besides, these methods only consider the discriminative power of selected features, while neglecting their redundancy. In this paper, we propose an Adaptive Collaborative Correlation lEarning-based Semi-Supervised Multi-label Feature Selection (Access-MFS) method to address these issues. Specifically, a generalized regression model equipped with an extended uncorrelated constraint is introduced to select discriminative yet irrelevant features and maintain consistency between predicted and ground-truth labels in labeled data, simultaneously. Then, the instance correlation and label correlation are integrated into the proposed regression model to adaptively learn both the sample similarity graph and the label similarity graph, which mutually enhance feature selection performance. Extensive experimental results demonstrate the superiority of the proposed Access-MFS over other state-of-the-art methods.
C$^{2}$IMUFS: Complementary and Consensus Learning-based Incomplete Multi-view Unsupervised Feature Selection
Aug 20, 2022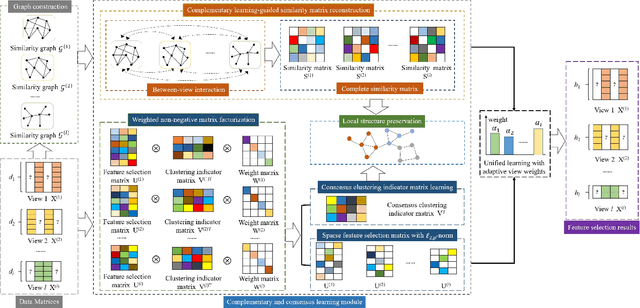
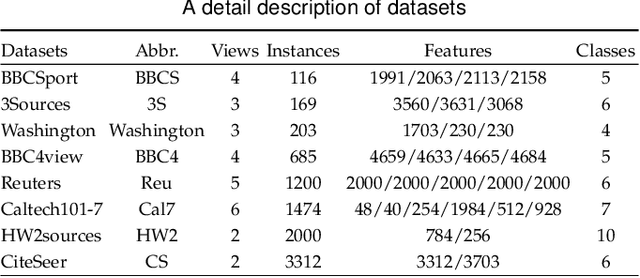
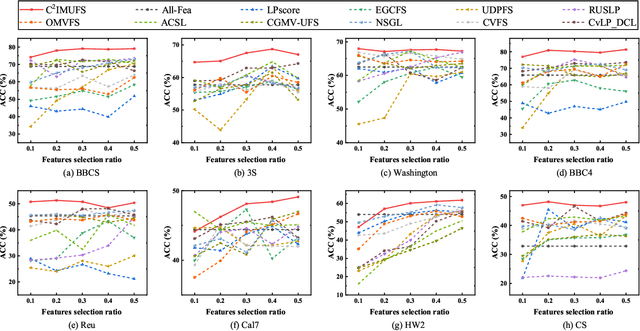
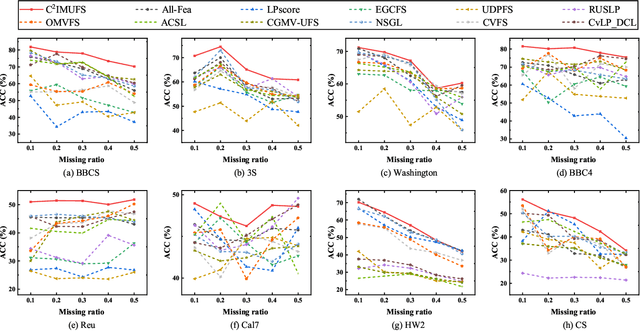
Multi-view unsupervised feature selection (MUFS) has been demonstrated as an effective technique to reduce the dimensionality of multi-view unlabeled data. The existing methods assume that all of views are complete. However, multi-view data are usually incomplete, i.e., a part of instances are presented on some views but not all views. Besides, learning the complete similarity graph, as an important promising technology in existing MUFS methods, cannot achieve due to the missing views. In this paper, we propose a complementary and consensus learning-based incomplete multi-view unsupervised feature selection method (C$^{2}$IMUFS) to address the aforementioned issues. Concretely, C$^{2}$IMUFS integrates feature selection into an extended weighted non-negative matrix factorization model equipped with adaptive learning of view-weights and a sparse $\ell_{2,p}$-norm, which can offer better adaptability and flexibility. By the sparse linear combinations of multiple similarity matrices derived from different views, a complementary learning-guided similarity matrix reconstruction model is presented to obtain the complete similarity graph in each view. Furthermore, C$^{2}$IMUFS learns a consensus clustering indicator matrix across different views and embeds it into a spectral graph term to preserve the local geometric structure. Comprehensive experimental results on real-world datasets demonstrate the effectiveness of C$^{2}$IMUFS compared with state-of-the-art methods.
Incremental Unsupervised Feature Selection for Dynamic Incomplete Multi-view Data
Apr 05, 2022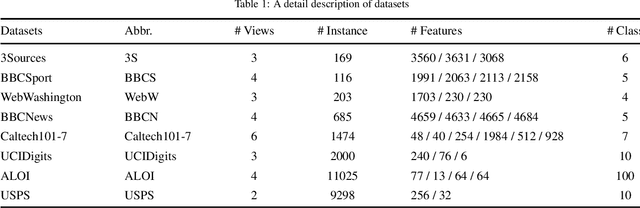
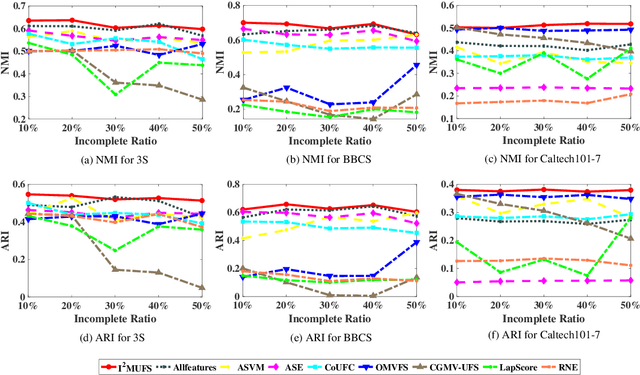
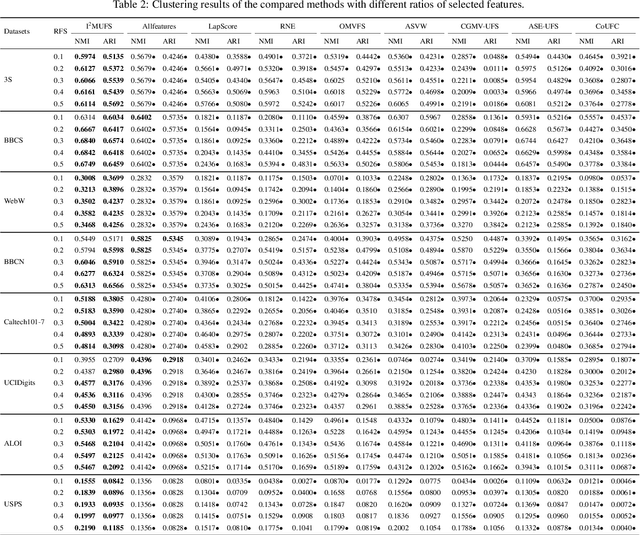
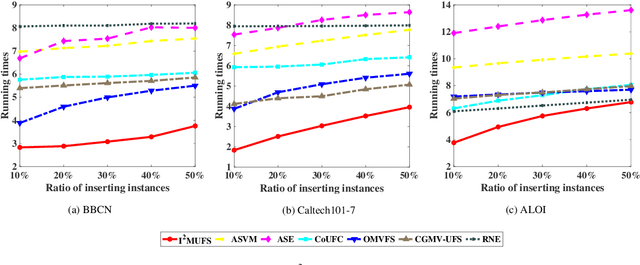
Multi-view unsupervised feature selection has been proven to be efficient in reducing the dimensionality of multi-view unlabeled data with high dimensions. The previous methods assume all of the views are complete. However, in real applications, the multi-view data are often incomplete, i.e., some views of instances are missing, which will result in the failure of these methods. Besides, while the data arrive in form of streams, these existing methods will suffer the issues of high storage cost and expensive computation time. To address these issues, we propose an Incremental Incomplete Multi-view Unsupervised Feature Selection method (I$^2$MUFS) on incomplete multi-view streaming data. By jointly considering the consistent and complementary information across different views, I$^2$MUFS embeds the unsupervised feature selection into an extended weighted non-negative matrix factorization model, which can learn a consensus clustering indicator matrix and fuse different latent feature matrices with adaptive view weights. Furthermore, we introduce the incremental leaning mechanisms to develop an alternative iterative algorithm, where the feature selection matrix is incrementally updated, rather than recomputing on the entire updated data from scratch. A series of experiments are conducted to verify the effectiveness of the proposed method by comparing with several state-of-the-art methods. The experimental results demonstrate the effectiveness and efficiency of the proposed method in terms of the clustering metrics and the computational cost.
Predicting Citywide Crowd Flows in Irregular Regions Using Multi-View Graph Convolutional Networks
Mar 19, 2019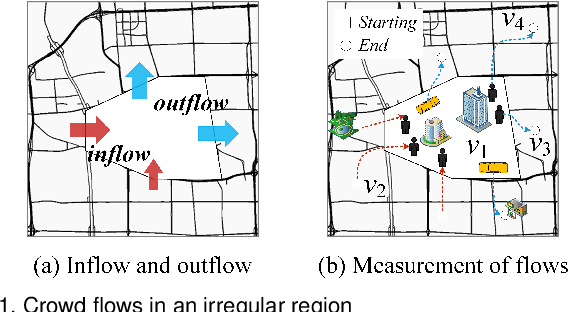

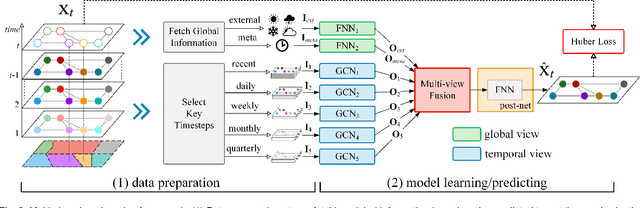
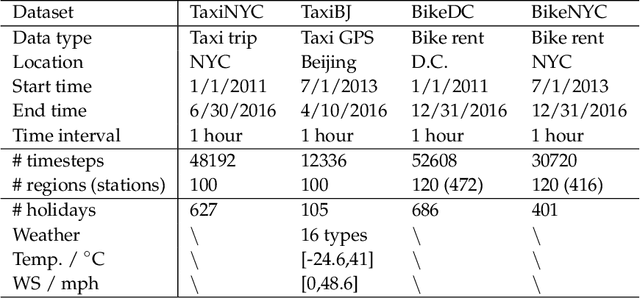
Being able to predict the crowd flows in each and every part of a city, especially in irregular regions, is strategically important for traffic control, risk assessment, and public safety. However, it is very challenging because of interactions and spatial correlations between different regions. In addition, it is affected by many factors: i) multiple temporal correlations among different time intervals: closeness, period, trend; ii) complex external influential factors: weather, events; iii) meta features: time of the day, day of the week, and so on. In this paper, we formulate crowd flow forecasting in irregular regions as a spatio-temporal graph (STG) prediction problem in which each node represents a region with time-varying flows. By extending graph convolution to handle the spatial information, we propose using spatial graph convolution to build a multi-view graph convolutional network (MVGCN) for the crowd flow forecasting problem, where different views can capture different factors as mentioned above. We evaluate MVGCN using four real-world datasets (taxicabs and bikes) and extensive experimental results show that our approach outperforms the adaptations of state-of-the-art methods. And we have developed a crowd flow forecasting system for irregular regions that can now be used internally.
HyperST-Net: Hypernetworks for Spatio-Temporal Forecasting
Sep 28, 2018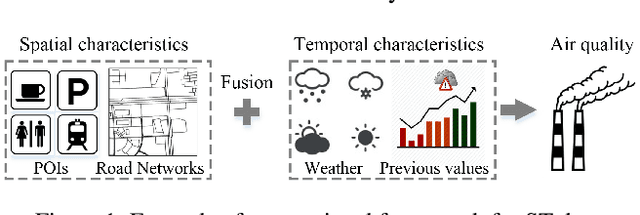
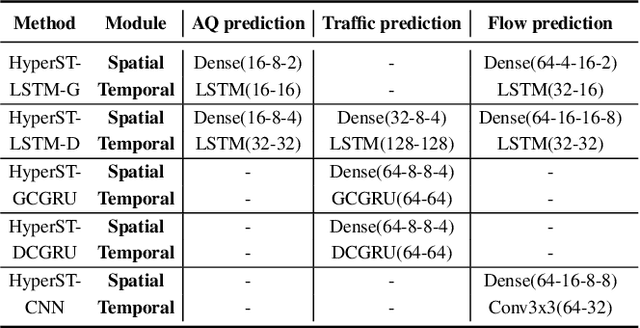

Spatio-temporal (ST) data, which represent multiple time series data corresponding to different spatial locations, are ubiquitous in real-world dynamic systems, such as air quality readings. Forecasting over ST data is of great importance but challenging as it is affected by many complex factors, including spatial characteristics, temporal characteristics and the intrinsic causality between them. In this paper, we propose a general framework (HyperST-Net) based on hypernetworks for deep ST models. More specifically, it consists of three major modules: a spatial module, a temporal module and a deduction module. Among them, the deduction module derives the parameter weights of the temporal module from the spatial characteristics, which are extracted by the spatial module. Then, we design a general form of HyperST layer as well as different forms for several basic layers in neural networks, including the dense layer (HyperST-Dense) and the convolutional layer (HyperST-Conv). Experiments on three types of real-world tasks demonstrate that the predictive models integrated with our framework achieve significant improvements, and outperform the state-of-the-art baselines as well.
Predicting Citywide Crowd Flows Using Deep Spatio-Temporal Residual Networks
Jan 10, 2017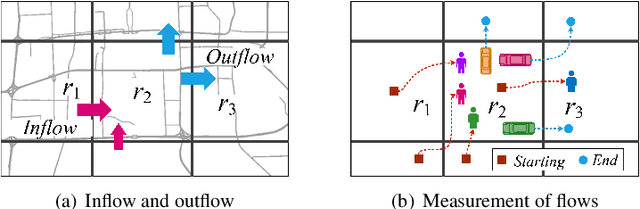

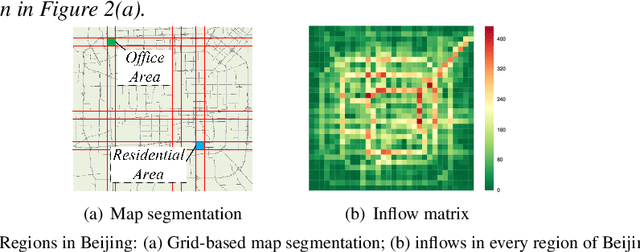
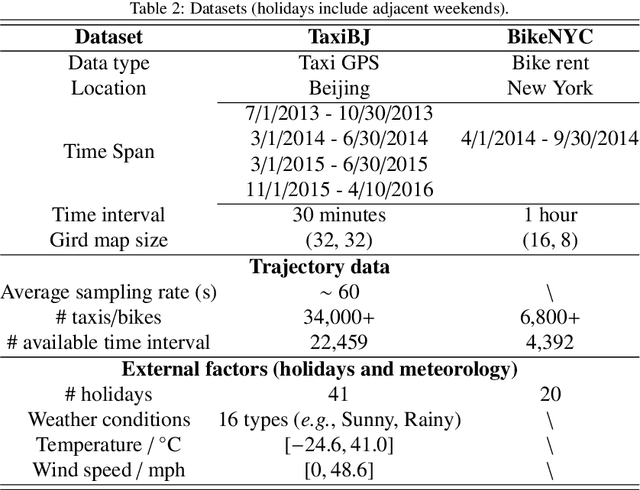
Forecasting the flow of crowds is of great importance to traffic management and public safety, and very challenging as it is affected by many complex factors, including spatial dependencies (nearby and distant), temporal dependencies (closeness, period, trend), and external conditions (e.g., weather and events). We propose a deep-learning-based approach, called ST-ResNet, to collectively forecast two types of crowd flows (i.e. inflow and outflow) in each and every region of a city. We design an end-to-end structure of ST-ResNet based on unique properties of spatio-temporal data. More specifically, we employ the residual neural network framework to model the temporal closeness, period, and trend properties of crowd traffic. For each property, we design a branch of residual convolutional units, each of which models the spatial properties of crowd traffic. ST-ResNet learns to dynamically aggregate the output of the three residual neural networks based on data, assigning different weights to different branches and regions. The aggregation is further combined with external factors, such as weather and day of the week, to predict the final traffic of crowds in each and every region. We have developed a real-time system based on Microsoft Azure Cloud, called UrbanFlow, providing the crowd flow monitoring and forecasting in Guiyang City of China. In addition, we present an extensive experimental evaluation using two types of crowd flows in Beijing and New York City (NYC), where ST-ResNet outperforms nine well-known baselines.