 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Alignment-based Multi-view Unsupervised Feature Selection with Sample-level Adaptive Graph Learning
Jan 12, 2026Although multi-view unsupervised feature selection (MUFS) has demonstrated success in dimensionality reduction for unlabeled multi-view data, most existing methods reduce feature redundancy by focusing on linear correlations among features but often overlook complex nonlinear dependencies. This limits the effectiveness of feature selection. In addition, existing methods fuse similarity graphs from multiple views by employing sample-invariant weights to preserve local structure. However, this process fails to account for differences in local neighborhood clarity among samples within each view, thereby hindering accurate characterization of the intrinsic local structure of the data. In this paper, we propose a Kernel Alignment-based multi-view unsupervised FeatUre selection with Sample-level adaptive graph lEarning method (KAFUSE) to address these issues. Specifically, we first employ kernel alignment with an orthogonal constraint to reduce feature redundancy in both linear and nonlinear relationships. Then, a cross-view consistent similarity graph is learned by applying sample-level fusion to each slice of a tensor formed by stacking similarity graphs from different views, which automatically adjusts the view weights for each sample during fusion. These two steps are integrated into a unified model for feature selection, enabling mutual enhancement between them. Extensive experiments on real multi-view datasets demonstrate the superiority of KAFUSE over state-of-the-art methods.
Cross-view Joint Learning for Mixed-Missing Multi-view Unsupervised Feature Selection
Nov 15, 2025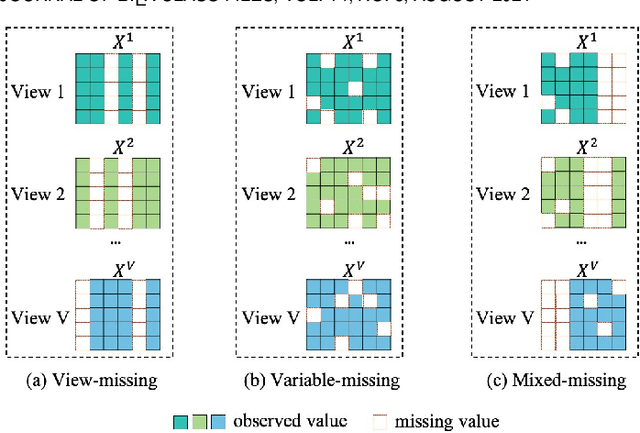
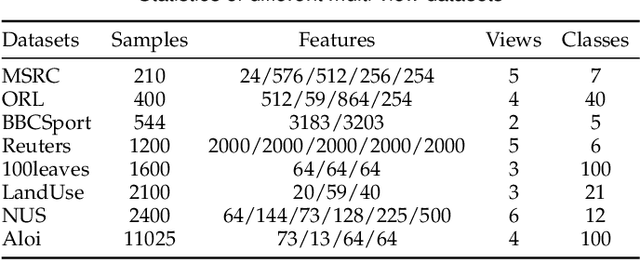
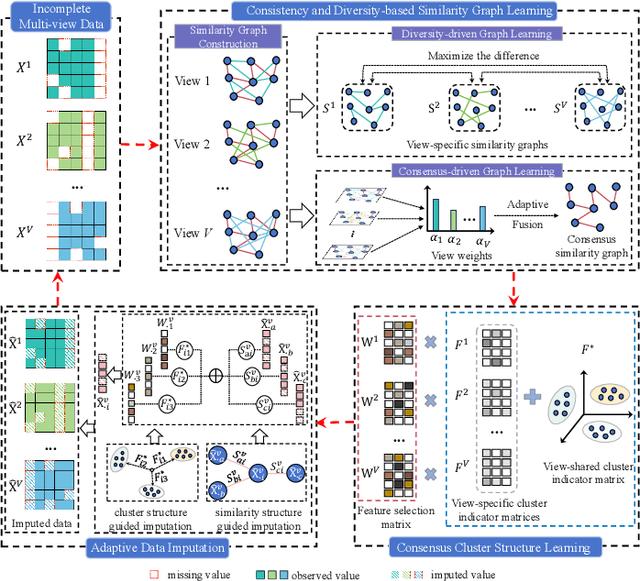
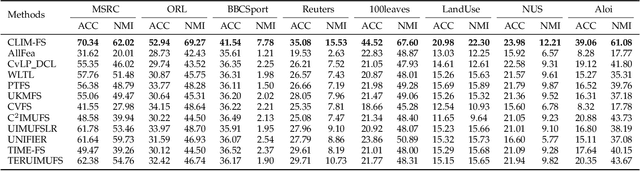
Incomplete multi-view unsupervised feature selection (IMUFS), which aims to identify representative features from unlabeled multi-view data containing missing values, has received growing attention in recent years. Despite their promising performance, existing methods face three key challenges: 1) by focusing solely on the view-missing problem, they are not well-suited to the more prevalent mixed-missing scenario in practice, where some samples lack entire views or only partial features within views; 2) insufficient utilization of consistency and diversity across views limits the effectiveness of feature selection; and 3) the lack of theoretical analysis makes it unclear how feature selection and data imputation interact during the joint learning process. Being aware of these, we propose CLIM-FS, a novel IMUFS method designed to address the mixed-missing problem. Specifically, we integrate the imputation of both missing views and variables into a feature selection model based on nonnegative orthogonal matrix factorization, enabling the joint learning of feature selection and adaptive data imputation. Furthermore, we fully leverage consensus cluster structure and cross-view local geometrical structure to enhance the synergistic learning process. We also provide a theoretical analysis to clarify the underlying collaborative mechanism of CLIM-FS. Experimental results on eight real-world multi-view datasets demonstrate that CLIM-FS outperforms state-of-the-art methods.
Causally-Aware Unsupervised Feature Selection Learning
Oct 16, 2024



Unsupervised feature selection (UFS) has recently gained attention for its effectiveness in processing unlabeled high-dimensional data. However, existing methods overlook the intrinsic causal mechanisms within the data, resulting in the selection of irrelevant features and poor interpretability. Additionally, previous graph-based methods fail to account for the differing impacts of non-causal and causal features in constructing the similarity graph, which leads to false links in the generated graph. To address these issues, a novel UFS method, called Causally-Aware UnSupErvised Feature Selection learning (CAUSE-FS), is proposed. CAUSE-FS introduces a novel causal regularizer that reweights samples to balance the confounding distribution of each treatment feature. This regularizer is subsequently integrated into a generalized unsupervised spectral regression model to mitigate spurious associations between features and clustering labels, thus achieving causal feature selection. Furthermore, CAUSE-FS employs causality-guided hierarchical clustering to partition features with varying causal contributions into multiple granularities. By integrating similarity graphs learned adaptively at different granularities, CAUSE-FS increases the importance of causal features when constructing the fused similarity graph to capture the reliable local structure of data. Extensive experimental results demonstrate the superiority of CAUSE-FS over state-of-the-art methods, with its interpretability further validated through feature visualization.
Unified View Imputation and Feature Selection Learning for Incomplete Multi-view Data
Jan 19, 2024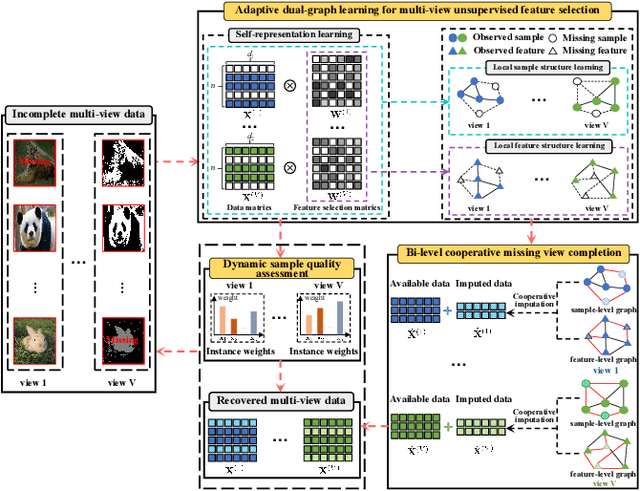
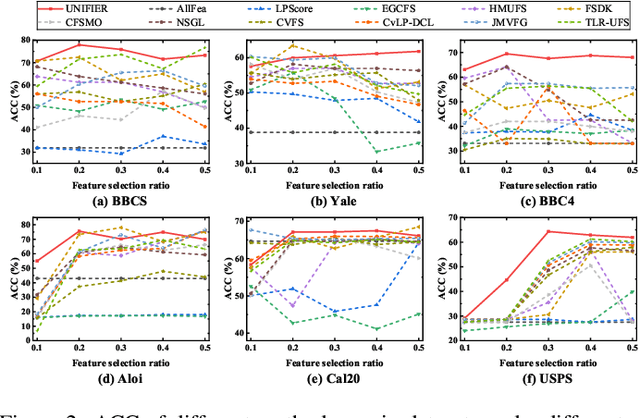
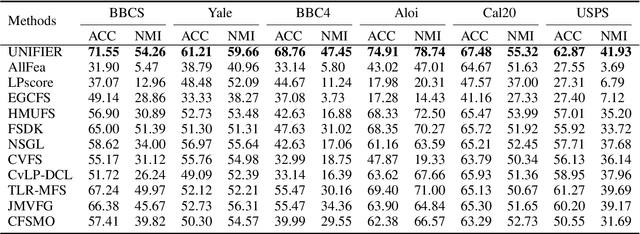
Although multi-view unsupervised feature selection (MUFS) is an effective technology for reducing dimensionality in machine learning, existing methods cannot directly deal with incomplete multi-view data where some samples are missing in certain views. These methods should first apply predetermined values to impute missing data, then perform feature selection on the complete dataset. Separating imputation and feature selection processes fails to capitalize on the potential synergy where local structural information gleaned from feature selection could guide the imputation, thereby improving the feature selection performance in turn. Additionally, previous methods only focus on leveraging samples' local structure information, while ignoring the intrinsic locality of the feature space. To tackle these problems, a novel MUFS method, called UNified view Imputation and Feature selectIon lEaRning (UNIFIER), is proposed. UNIFIER explores the local structure of multi-view data by adaptively learning similarity-induced graphs from both the sample and feature spaces. Then, UNIFIER dynamically recovers the missing views, guided by the sample and feature similarity graphs during the feature selection procedure. Furthermore, the half-quadratic minimization technique is used to automatically weight different instances, alleviating the impact of outliers and unreliable restored data. Comprehensive experimental results demonstrate that UNIFIER outperforms other state-of-the-art methods.
C$^{2}$IMUFS: Complementary and Consensus Learning-based Incomplete Multi-view Unsupervised Feature Selection
Aug 20, 2022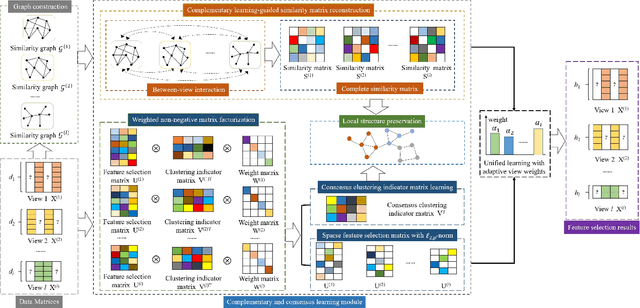
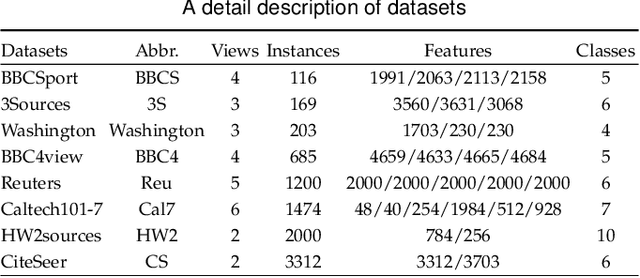
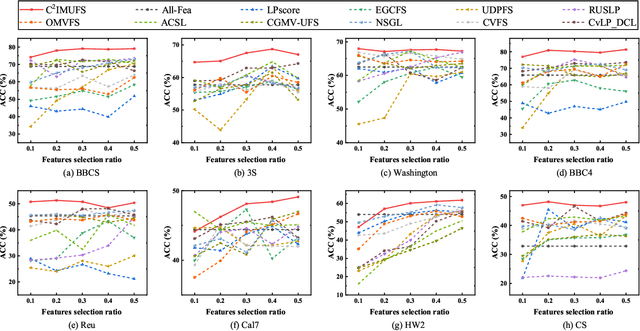
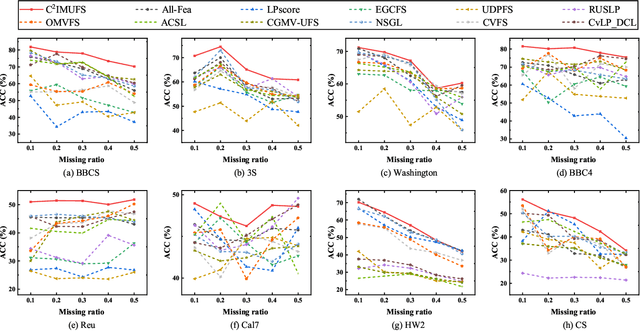
Multi-view unsupervised feature selection (MUFS) has been demonstrated as an effective technique to reduce the dimensionality of multi-view unlabeled data. The existing methods assume that all of views are complete. However, multi-view data are usually incomplete, i.e., a part of instances are presented on some views but not all views. Besides, learning the complete similarity graph, as an important promising technology in existing MUFS methods, cannot achieve due to the missing views. In this paper, we propose a complementary and consensus learning-based incomplete multi-view unsupervised feature selection method (C$^{2}$IMUFS) to address the aforementioned issues. Concretely, C$^{2}$IMUFS integrates feature selection into an extended weighted non-negative matrix factorization model equipped with adaptive learning of view-weights and a sparse $\ell_{2,p}$-norm, which can offer better adaptability and flexibility. By the sparse linear combinations of multiple similarity matrices derived from different views, a complementary learning-guided similarity matrix reconstruction model is presented to obtain the complete similarity graph in each view. Furthermore, C$^{2}$IMUFS learns a consensus clustering indicator matrix across different views and embeds it into a spectral graph term to preserve the local geometric structure. Comprehensive experimental results on real-world datasets demonstrate the effectiveness of C$^{2}$IMUFS compared with state-of-the-art methods.
Adaptive Graph-based Generalized Regression Model for Unsupervised Feature Selection
Dec 27, 2020
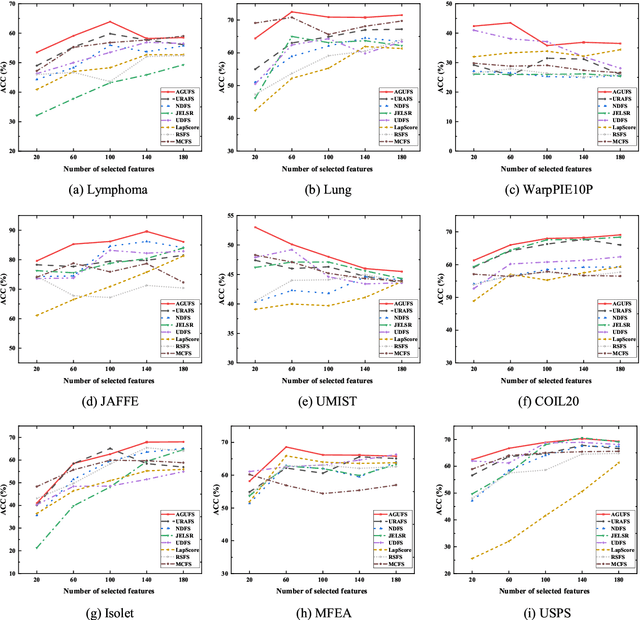
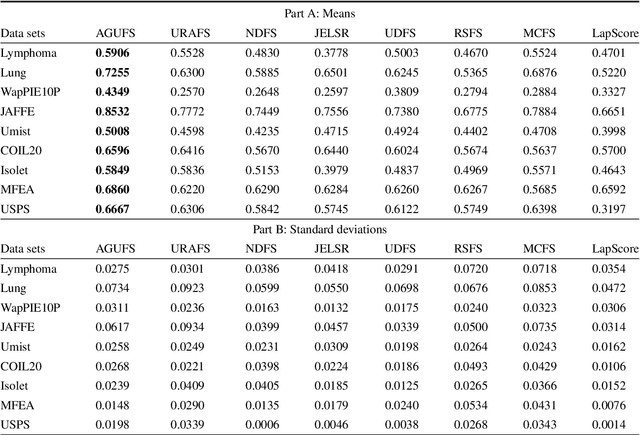
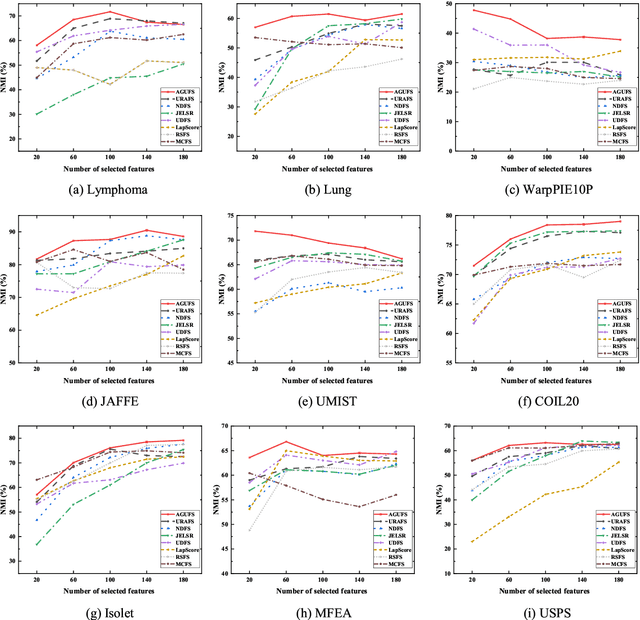
Unsupervised feature selection is an important method to reduce dimensions of high dimensional data without labels, which is benefit to avoid ``curse of dimensionality'' and improve the performance of subsequent machine learning tasks, like clustering and retrieval. How to select the uncorrelated and discriminative features is the key problem of unsupervised feature selection. Many proposed methods select features with strong discriminant and high redundancy, or vice versa. However, they only satisfy one of these two criteria. Other existing methods choose the discriminative features with low redundancy by constructing the graph matrix on the original feature space. Since the original feature space usually contains redundancy and noise, it will degrade the performance of feature selection. In order to address these issues, we first present a novel generalized regression model imposed by an uncorrelated constraint and the $\ell_{2,1}$-norm regularization. It can simultaneously select the uncorrelated and discriminative features as well as reduce the variance of these data points belonging to the same neighborhood, which is help for the clustering task. Furthermore, the local intrinsic structure of data is constructed on the reduced dimensional space by learning the similarity-induced graph adaptively. Then the learnings of the graph structure and the indicator matrix based on the spectral analysis are integrated into the generalized regression model. Finally, we develop an alternative iterative optimization algorithm to solve the objective function. A series of experiments are carried out on nine real-world data sets to demonstrate the effectiveness of the proposed method in comparison with other competing approaches.