 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent Advances of End-to-End Video Coding Technologies for AVS Standard Development
Jan 31, 2026Video coding standards are essential to enable the interoperability and widespread adoption of efficient video compression technologies. In pursuit of greater video compression efficiency, the AVS video coding working group launched the standardization exploration of end-to-end intelligent video coding, establishing the AVS End-to-End Intelligent Video Coding Exploration Model (AVS-EEM) project. A core design principle of AVS-EEM is its focus on practical deployment, featuring inherently low computational complexity and requiring strict adherence to the common test conditions of conventional video coding. This paper details the development history of AVS-EEM and provides a systematic introduction to its key technical framework, covering model architectures, training strategies, and inference optimizations. These innovations have collectively driven the project's rapid performance evolution, enabling continuous and significant gains under strict complexity constraints. Through over two years of iterative refinement and collaborative effort, the coding performance of AVS-EEM has seen substantial improvement. Experimental results demonstrate that its latest model achieves superior compression efficiency compared to the conventional AVS3 reference software, marking a significant step toward a deployable intelligent video coding standard.
Neural Video Compression with Context Modulation
May 20, 2025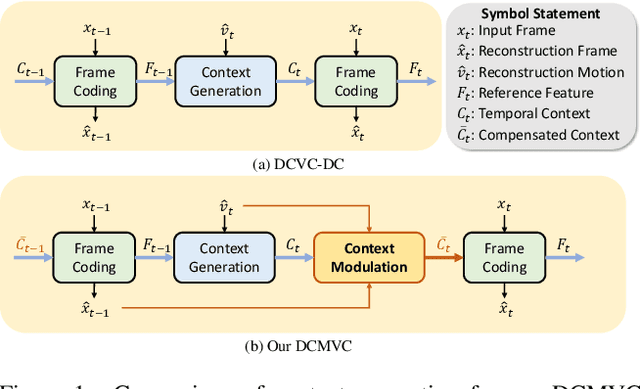
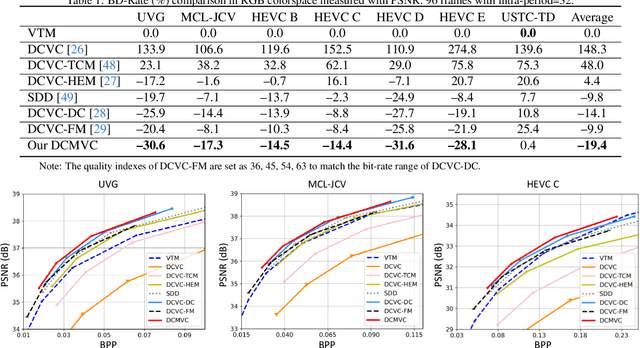
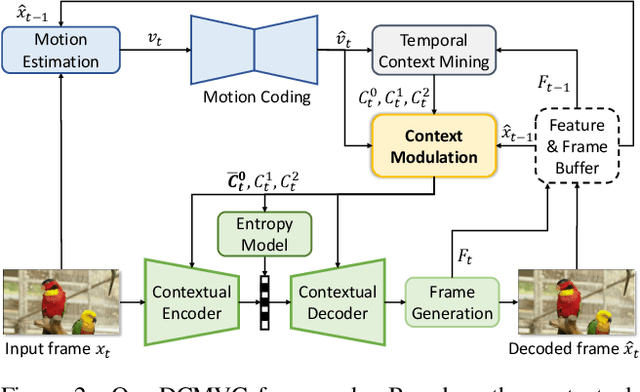
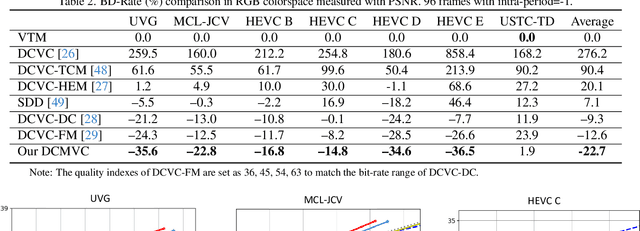
Efficient video coding is highly dependent on exploiting the temporal redundancy, which is usually achieved by extracting and leveraging the temporal context in the emerging conditional coding-based neural video codec (NVC). Although the latest NVC has achieved remarkable progress in improving the compression performance, the inherent temporal context propagation mechanism lacks the ability to sufficiently leverage the reference information, limiting further improvement. In this paper, we address the limitation by modulating the temporal context with the reference frame in two steps. Specifically, we first propose the flow orientation to mine the inter-correlation between the reference frame and prediction frame for generating the additional oriented temporal context. Moreover, we introduce the context compensation to leverage the oriented context to modulate the propagated temporal context generated from the propagated reference feature. Through the synergy mechanism and decoupling loss supervision, the irrelevant propagated information can be effectively eliminated to ensure better context modeling. Experimental results demonstrate that our codec achieves on average 22.7% bitrate reduction over the advanced traditional video codec H.266/VVC, and offers an average 10.1% bitrate saving over the previous state-of-the-art NVC DCVC-FM. The code is available at https://github.com/Austin4USTC/DCMVC.
Augmented Deep Contexts for Spatially Embedded Video Coding
May 08, 2025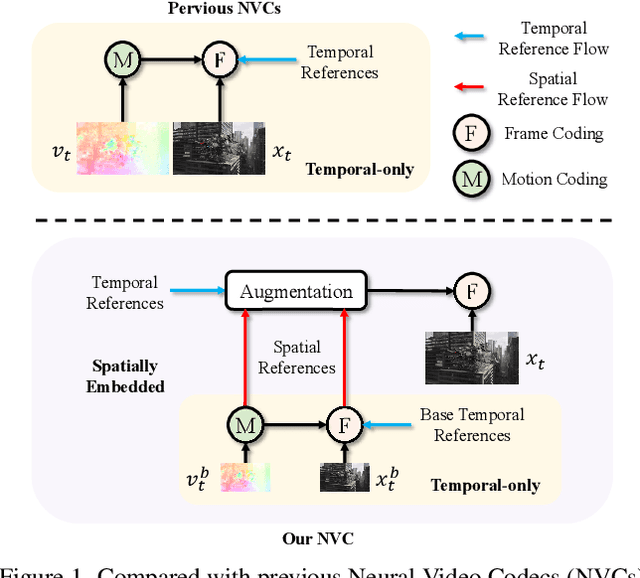
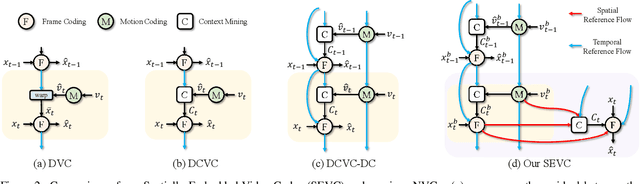
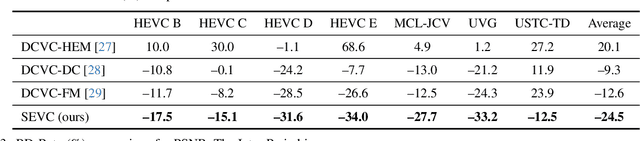
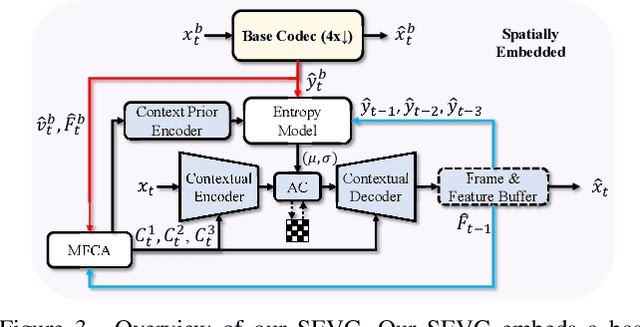
Most Neural Video Codecs (NVCs) only employ temporal references to generate temporal-only contexts and latent prior. These temporal-only NVCs fail to handle large motions or emerging objects due to limited contexts and misaligned latent prior. To relieve the limitations, we propose a Spatially Embedded Video Codec (SEVC), in which the low-resolution video is compressed for spatial references. Firstly, our SEVC leverages both spatial and temporal references to generate augmented motion vectors and hybrid spatial-temporal contexts. Secondly, to address the misalignment issue in latent prior and enrich the prior information, we introduce a spatial-guided latent prior augmented by multiple temporal latent representations. At last, we design a joint spatial-temporal optimization to learn quality-adaptive bit allocation for spatial references, further boosting rate-distortion performance. Experimental results show that our SEVC effectively alleviates the limitations in handling large motions or emerging objects, and also reduces 11.9% more bitrate than the previous state-of-the-art NVC while providing an additional low-resolution bitstream. Our code and model are available at https://github.com/EsakaK/SEVC.
USTC-TD: A Test Dataset and Benchmark for Image and Video Coding in 2020s
Sep 13, 2024



Image/video coding has been a remarkable research area for both academia and industry for many years. Testing datasets, especially high-quality image/video datasets are desirable for the justified evaluation of coding-related research, practical applications, and standardization activities. We put forward a test dataset namely USTC-TD, which has been successfully adopted in the practical end-to-end image/video coding challenge of the IEEE International Conference on Visual Communications and Image Processing in 2022 and 2023. USTC-TD contains 40 images at 4K spatial resolution and 10 video sequences at 1080p spatial resolution, featuring various content due to the diverse environmental factors (scene type, texture, motion, view) and the designed imaging factors (illumination, shadow, lens). We quantitatively evaluate USTC-TD on different image/video features (spatial, temporal, color, lightness), and compare it with the previous image/video test datasets, which verifies the wider coverage and more diversity of the proposed dataset. We also evaluate both classic standardized and recent learned image/video coding schemes on USTC-TD with PSNR and MS-SSIM, and provide an extensive benchmark for the evaluated schemes. Based on the characteristics and specific design of the proposed test dataset, we analyze the benchmark performance and shed light on the future research and development of image/video coding. All the data are released online: https://esakak.github.io/USTC-TD.
NVC-1B: A Large Neural Video Coding Model
Jul 28, 2024



The emerging large models have achieved notable progress in the fields of natural language processing and computer vision. However, large models for neural video coding are still unexplored. In this paper, we try to explore how to build a large neural video coding model. Based on a small baseline model, we gradually scale up the model sizes of its different coding parts, including the motion encoder-decoder, motion entropy model, contextual encoder-decoder, contextual entropy model, and temporal context mining module, and analyze the influence of model sizes on video compression performance. Then, we explore to use different architectures, including CNN, mixed CNN-Transformer, and Transformer architectures, to implement the neural video coding model and analyze the influence of model architectures on video compression performance. Based on our exploration results, we design the first neural video coding model with more than 1 billion parameters -- NVC-1B. Experimental results show that our proposed large model achieves a significant video compression performance improvement over the small baseline model, and represents the state-of-the-art compression efficiency. We anticipate large models may bring up the video coding technologies to the next level.
Uniformly Accelerated Motion Model for Inter Prediction
Jul 16, 2024



Inter prediction is a key technology to reduce the temporal redundancy in video coding. In natural videos, there are usually multiple moving objects with variable velocity, resulting in complex motion fields that are difficult to represent compactly. In Versatile Video Coding (VVC), existing inter prediction methods usually assume uniform speed motion between consecutive frames and use the linear models for motion estimation (ME) and motion compensation (MC), which may not well handle the complex motion fields in the real world. To address these issues, we introduce a uniformly accelerated motion model (UAMM) to exploit motion-related elements (velocity, acceleration) of moving objects between the video frames, and further combine them to assist the inter prediction methods to handle the variable motion in the temporal domain. Specifically, first, the theory of UAMM is mentioned. Second, based on that, we propose the UAMM-based parameter derivation and extrapolation schemes in the coding process. Third, we integrate the UAMM into existing inter prediction modes (Merge, MMVD, CIIP) to achieve higher prediction accuracy. The proposed method is implemented into the VVC reference software, VTM version 12.0. Experimental results show that the proposed method achieves up to 0.38% and on average 0.13% BD-rate reduction compared to the VTM anchor, under the Low-delay P configuration, with a slight increase of time complexity on the encoding/decoding side.
Offline and Online Optical Flow Enhancement for Deep Video Compression
Jul 11, 2023



Video compression relies heavily on exploiting the temporal redundancy between video frames, which is usually achieved by estimating and using the motion information. The motion information is represented as optical flows in most of the existing deep video compression networks. Indeed, these networks often adopt pre-trained optical flow estimation networks for motion estimation. The optical flows, however, may be less suitable for video compression due to the following two factors. First, the optical flow estimation networks were trained to perform inter-frame prediction as accurately as possible, but the optical flows themselves may cost too many bits to encode. Second, the optical flow estimation networks were trained on synthetic data, and may not generalize well enough to real-world videos. We address the twofold limitations by enhancing the optical flows in two stages: offline and online. In the offline stage, we fine-tune a trained optical flow estimation network with the motion information provided by a traditional (non-deep) video compression scheme, e.g. H.266/VVC, as we believe the motion information of H.266/VVC achieves a better rate-distortion trade-off. In the online stage, we further optimize the latent features of the optical flows with a gradient descent-based algorithm for the video to be compressed, so as to enhance the adaptivity of the optical flows. We conduct experiments on a state-of-the-art deep video compression scheme, DCVC. Experimental results demonstrate that the proposed offline and online enhancement together achieves on average 12.8% bitrate saving on the tested videos, without increasing the model or computational complexity of the decoder side.