 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructEdit: Instruction-based Knowledge Editing for Large Language Models
Feb 25, 2024



Knowledge editing for large language models can offer an efficient solution to alter a model's behavior without negatively impacting the overall performance. However, the current approach encounters issues with limited generalizability across tasks, necessitating one distinct editor for each task, which significantly hinders the broader applications. To address this, we take the first step to analyze the multi-task generalization issue in knowledge editing. Specifically, we develop an instruction-based editing technique, termed InstructEdit, which facilitates the editor's adaptation to various task performances simultaneously using simple instructions. With only one unified editor for each LLM, we empirically demonstrate that InstructEdit can improve the editor's control, leading to an average 14.86% increase in Reliability in multi-task editing setting. Furthermore, experiments involving holdout unseen task illustrate that InstructEdit consistently surpass previous strong baselines. To further investigate the underlying mechanisms of instruction-based knowledge editing, we analyze the principal components of the editing gradient directions, which unveils that instructions can help control optimization direction with stronger OOD generalization. Code and datasets will be available in https://github.com/zjunlp/EasyEdit.
Semi-Supervised Cross-Silo Advertising with Partial Knowledge Transfer
May 31, 2022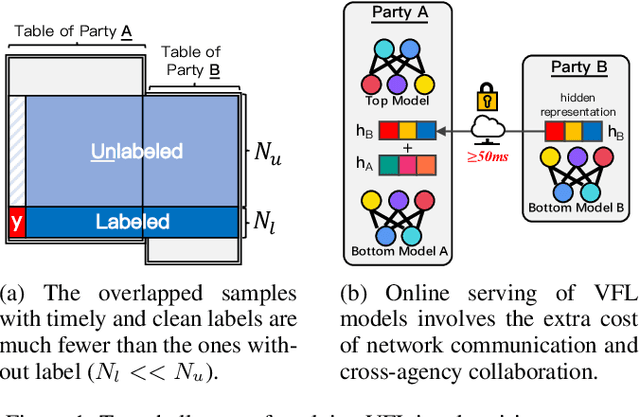
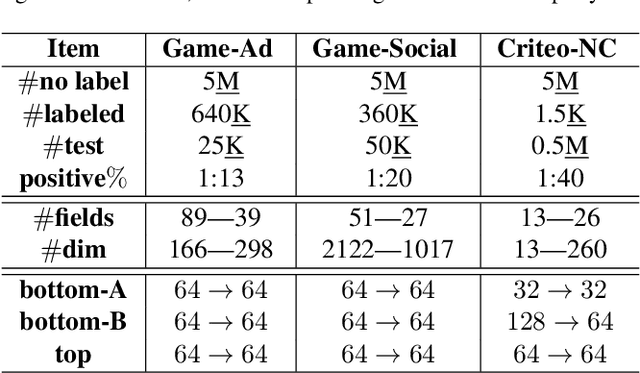
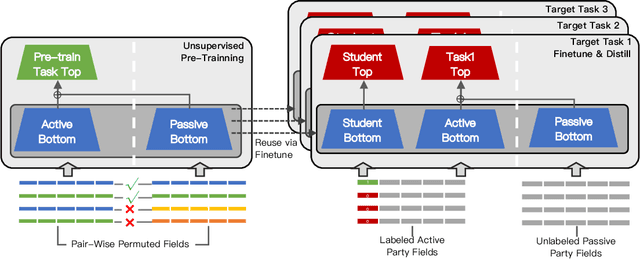
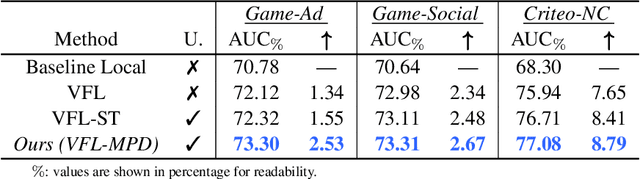
As an emerging secure learning paradigm in leveraging cross-agency private data, vertical federated learning (VFL) is expected to improve advertising models by enabling the joint learning of complementary user attributes privately owned by the advertiser and the publisher. However, there are two key challenges in applying it to advertising systems: a) the limited scale of labeled overlapping samples, and b) the high cost of real-time cross-agency serving. In this paper, we propose a semi-supervised split distillation framework VFed-SSD to alleviate the two limitations. We identify that: i) there are massive unlabeled overlapped data available in advertising systems, and ii) we can keep a balance between model performance and inference cost by decomposing the federated model. Specifically, we develop a self-supervised task Matched Pair Detection (MPD) to exploit the vertically partitioned unlabeled data and propose the Split Knowledge Distillation (SplitKD) schema to avoid cross-agency serving. Empirical studies on three industrial datasets exhibit the effectiveness of our methods, with the median AUC over all datasets improved by 0.86% and 2.6% in the local deployment mode and the federated deployment mode respectively. Overall, our framework provides an efficient federation-enhanced solution for real-time display advertising with minimal deploying cost and significant performance lift.