 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Cross-Silo Advertising with Partial Knowledge Transfer
Paper and Code
May 31, 2022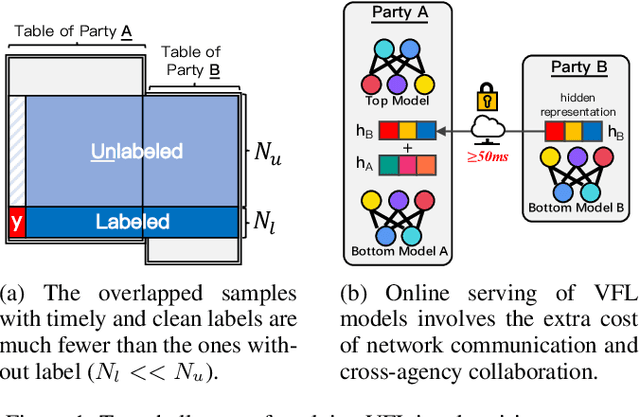
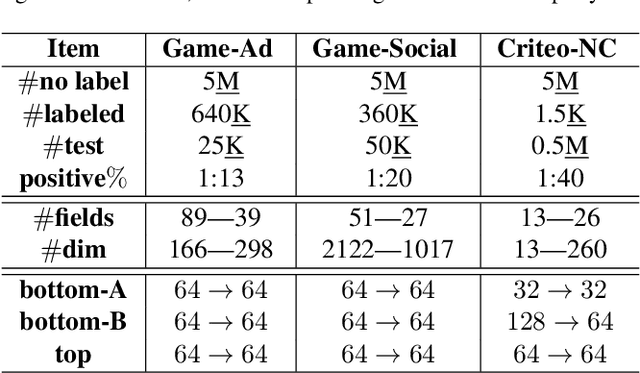
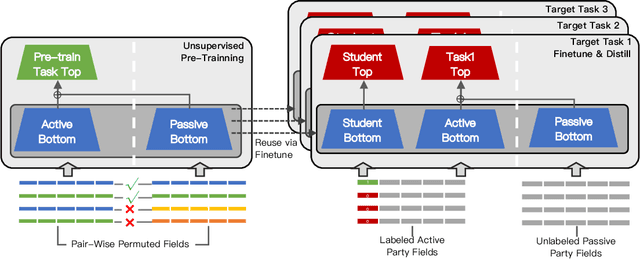
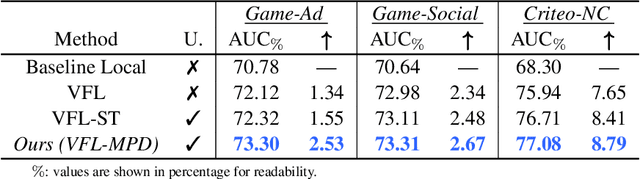
As an emerging secure learning paradigm in leveraging cross-agency private data, vertical federated learning (VFL) is expected to improve advertising models by enabling the joint learning of complementary user attributes privately owned by the advertiser and the publisher. However, there are two key challenges in applying it to advertising systems: a) the limited scale of labeled overlapping samples, and b) the high cost of real-time cross-agency serving. In this paper, we propose a semi-supervised split distillation framework VFed-SSD to alleviate the two limitations. We identify that: i) there are massive unlabeled overlapped data available in advertising systems, and ii) we can keep a balance between model performance and inference cost by decomposing the federated model. Specifically, we develop a self-supervised task Matched Pair Detection (MPD) to exploit the vertically partitioned unlabeled data and propose the Split Knowledge Distillation (SplitKD) schema to avoid cross-agency serving. Empirical studies on three industrial datasets exhibit the effectiveness of our methods, with the median AUC over all datasets improved by 0.86% and 2.6% in the local deployment mode and the federated deployment mode respectively. Overall, our framework provides an efficient federation-enhanced solution for real-time display advertising with minimal deploying cost and significant performance lift.