 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaser: Governing Long-Horizon Agentic Search via Structured Protocol and Context Register
Dec 23, 2025Recent advances in Large Language Models (LLMs) and Large Reasoning Models (LRMs) have enabled agentic search systems that interleave multi-step reasoning with external tool use. However, existing frameworks largely rely on unstructured natural-language reasoning and accumulate raw intermediate traces in the context, which often leads to unstable reasoning trajectories, context overflow, and degraded performance on complex multi-hop queries. In this study, we introduce Laser, a general framework for stabilizing and scaling agentic search. Laser defines a symbolic action protocol that organizes agent behaviors into three spaces: planning, task-solving, and retrospection. Each action is specified with explicit semantics and a deterministic execution format, enabling structured and logical reasoning processes and reliable action parsing. This design makes intermediate decisions interpretable and traceable, enhancing explicit retrospection and fine-grained control over reasoning trajectories. In coordination with parsable actions, Laser further maintains a compact context register that stores only essential states of the reasoning process, allowing the agent to reason over long horizons without uncontrolled context expansion. Experiments on Qwen2.5/3-series models across challenging multi-hop QA datasets show that Laser consistently outperforms existing agentic search baselines under both prompting-only and fine-tuning settings, demonstrating that Laser provides a principled and effective foundation for robust, scalable agentic search.
Vertical Semi-Federated Learning for Efficient Online Advertising
Sep 30, 2022
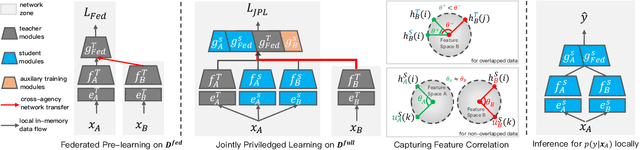
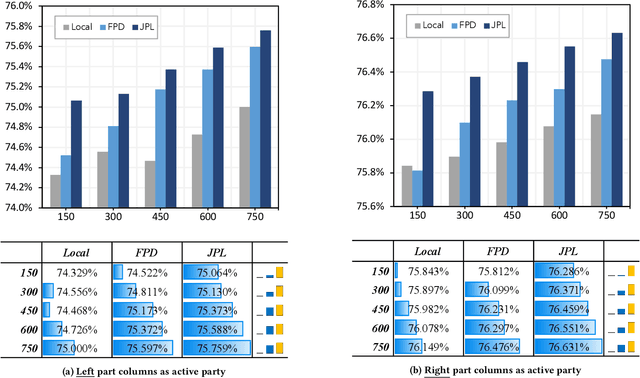

As an emerging secure learning paradigm in leveraging cross-silo private data, vertical federated learning (VFL) is expected to improve advertising models by enabling the joint learning of complementary user attributes privately owned by the advertiser and the publisher. However, the 1) restricted applicable scope to overlapped samples and 2) high system challenge of real-time federated serving have limited its application to advertising systems. In this paper, we advocate new learning setting Semi-VFL (Vertical Semi-Federated Learning) as a lightweight solution to utilize all available data (both the overlapped and non-overlapped data) that is free from federated serving. Semi-VFL is expected to perform better than single-party models and maintain a low inference cost. It's notably important to i) alleviate the absence of the passive party's feature and ii) adapt to the whole sample space to implement a good solution for Semi-VFL. Thus, we propose a carefully designed joint privileged learning framework (JPL) as an efficient implementation of Semi-VFL. Specifically, we build an inference-efficient single-party student model applicable to the whole sample space and meanwhile maintain the advantage of the federated feature extension. Novel feature imitation and ranking consistency restriction methods are proposed to extract cross-party feature correlations and maintain cross-sample-space consistency for both the overlapped and non-overlapped data. We conducted extensive experiments on real-world advertising datasets. The results show that our method achieves the best performance over baseline methods and validate its effectiveness in maintaining cross-view feature correlation.
Semi-Supervised Cross-Silo Advertising with Partial Knowledge Transfer
May 31, 2022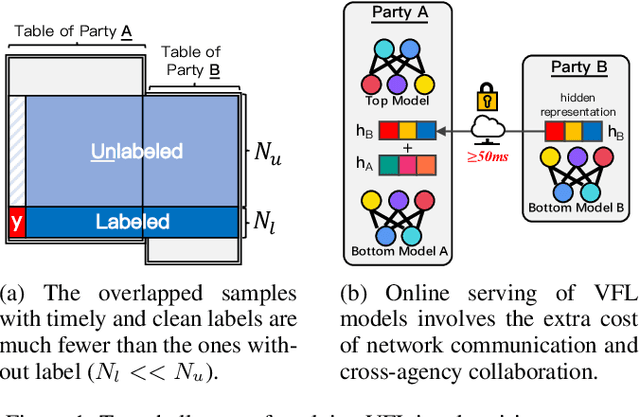
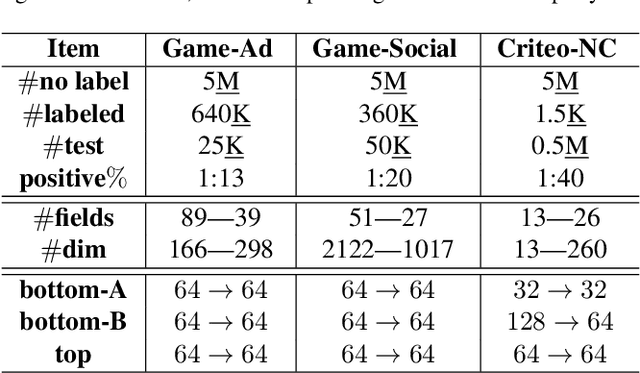
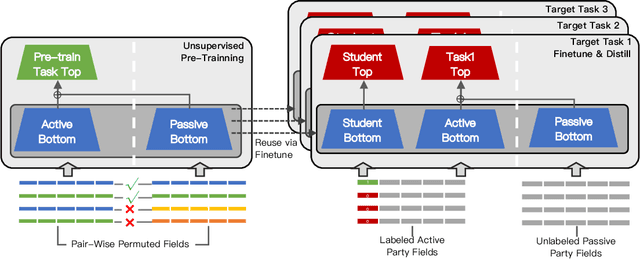
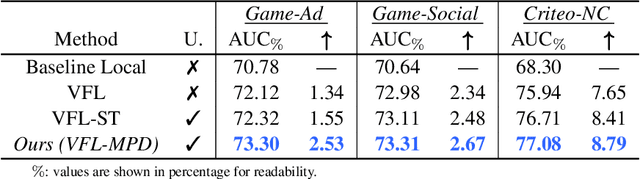
As an emerging secure learning paradigm in leveraging cross-agency private data, vertical federated learning (VFL) is expected to improve advertising models by enabling the joint learning of complementary user attributes privately owned by the advertiser and the publisher. However, there are two key challenges in applying it to advertising systems: a) the limited scale of labeled overlapping samples, and b) the high cost of real-time cross-agency serving. In this paper, we propose a semi-supervised split distillation framework VFed-SSD to alleviate the two limitations. We identify that: i) there are massive unlabeled overlapped data available in advertising systems, and ii) we can keep a balance between model performance and inference cost by decomposing the federated model. Specifically, we develop a self-supervised task Matched Pair Detection (MPD) to exploit the vertically partitioned unlabeled data and propose the Split Knowledge Distillation (SplitKD) schema to avoid cross-agency serving. Empirical studies on three industrial datasets exhibit the effectiveness of our methods, with the median AUC over all datasets improved by 0.86% and 2.6% in the local deployment mode and the federated deployment mode respectively. Overall, our framework provides an efficient federation-enhanced solution for real-time display advertising with minimal deploying cost and significant performance lift.
Multi-View Learning for Vision-and-Language Navigation
Mar 09, 2020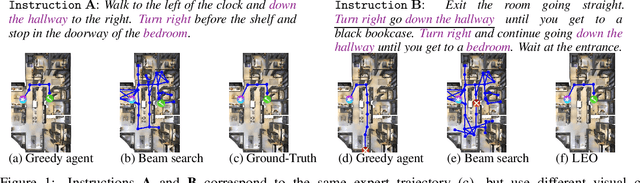
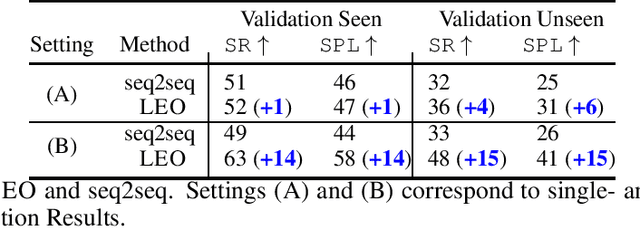
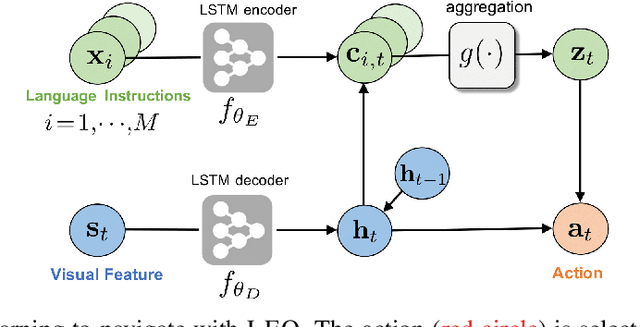
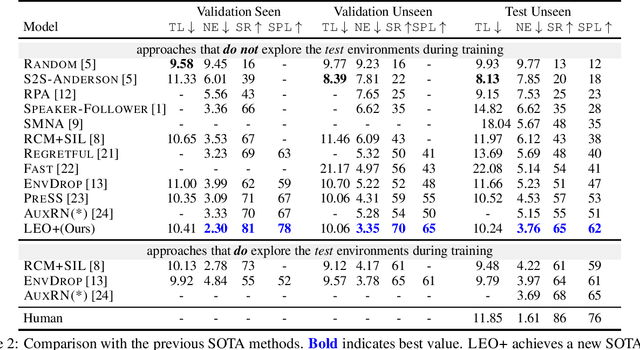
Learning to navigate in a visual environment following natural language instructions is a challenging task because natural language instructions are highly variable, ambiguous, and under-specified. In this paper, we present a novel training paradigm, Learn from EveryOne (LEO), which leverages multiple instructions (as different views) for the same trajectory to resolve language ambiguity and improve generalization. By sharing parameters across instructions, our approach learns more effectively from limited training data and generalizes better in unseen environments. On the recent Room-to-Room (R2R) benchmark dataset, LEO achieves 16% improvement (absolute) over a greedy agent as the base agent (25.3% $\rightarrow$ 41.4%) in Success Rate weighted by Path Length (SPL). Further, LEO is complementary to most existing models for vision-and-language navigation, allowing for easy integration with the existing techniques, leading to LEO+, which creates the new state of the art, pushing the R2R benchmark to 62% (9% absolute improvement).
XGPT: Cross-modal Generative Pre-Training for Image Captioning
Mar 04, 2020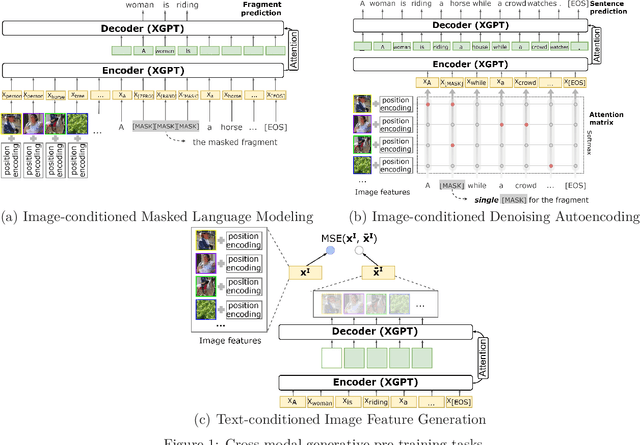
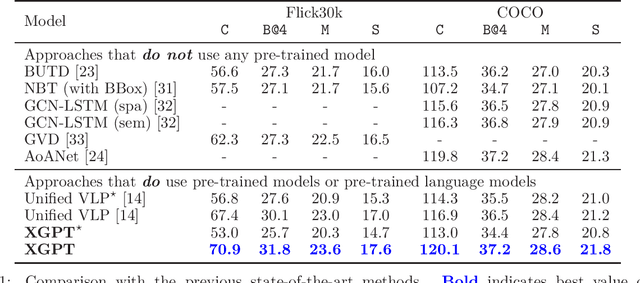
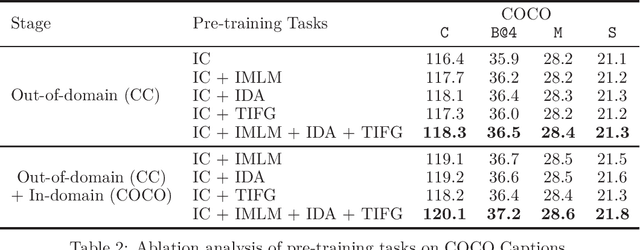
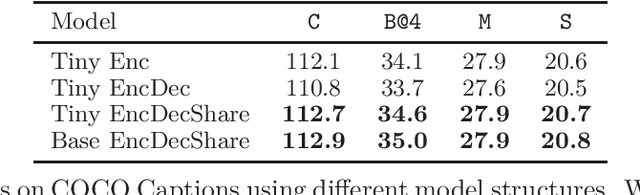
While many BERT-based cross-modal pre-trained models produce excellent results on downstream understanding tasks like image-text retrieval and VQA, they cannot be applied to generation tasks directly. In this paper, we propose XGPT, a new method of Cross-modal Generative Pre-Training for Image Captioning that is designed to pre-train text-to-image caption generators through three novel generation tasks, including Image-conditioned Masked Language Modeling (IMLM), Image-conditioned Denoising Autoencoding (IDA), and Text-conditioned Image Feature Generation (TIFG). As a result, the pre-trained XGPT can be fine-tuned without any task-specific architecture modifications to create state-of-the-art models for image captioning. Experiments show that XGPT obtains new state-of-the-art results on the benchmark datasets, including COCO Captions and Flickr30k Captions. We also use XGPT to generate new image captions as data augmentation for the image retrieval task and achieve significant improvement on all recall metrics.
Robust Navigation with Language Pretraining and Stochastic Sampling
Sep 05, 2019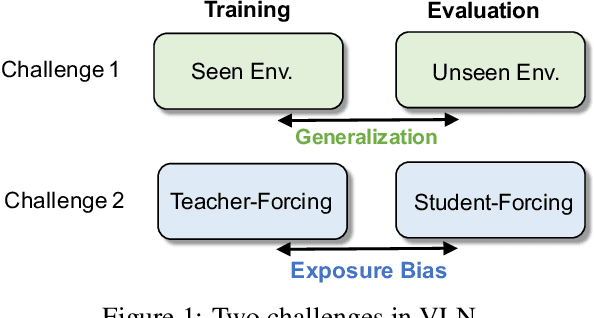
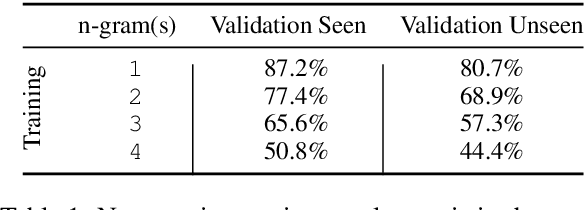
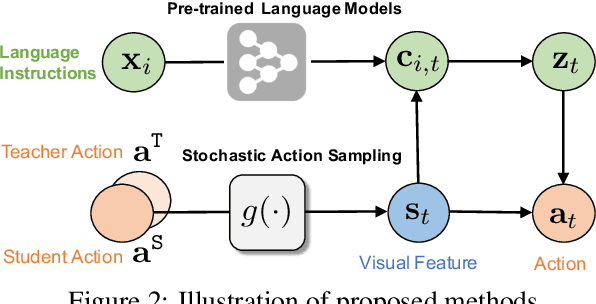
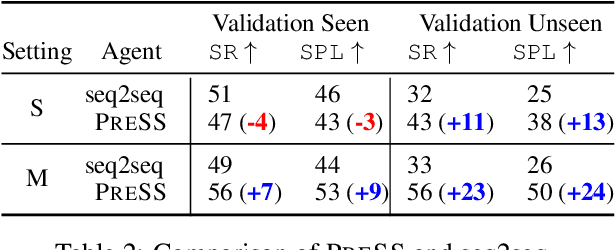
Core to the vision-and-language navigation (VLN) challenge is building robust instruction representations and action decoding schemes, which can generalize well to previously unseen instructions and environments. In this paper, we report two simple but highly effective methods to address these challenges and lead to a new state-of-the-art performance. First, we adapt large-scale pretrained language models to learn text representations that generalize better to previously unseen instructions. Second, we propose a stochastic sampling scheme to reduce the considerable gap between the expert actions in training and sampled actions in test, so that the agent can learn to correct its own mistakes during long sequential action decoding. Combining the two techniques, we achieve a new state of the art on the Room-to-Room benchmark with 6% absolute gain over the previous best result (47% -> 53%) on the Success Rate weighted by Path Length metric.
Incorporating Glosses into Neural Word Sense Disambiguation
Jul 16, 2018
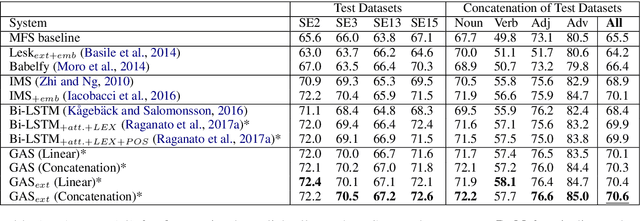

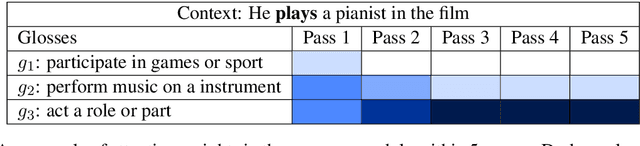
Word Sense Disambiguation (WSD) aims to identify the correct meaning of polysemous words in the particular context. Lexical resources like WordNet which are proved to be of great help for WSD in the knowledge-based methods. However, previous neural networks for WSD always rely on massive labeled data (context), ignoring lexical resources like glosses (sense definitions). In this paper, we integrate the context and glosses of the target word into a unified framework in order to make full use of both labeled data and lexical knowledge. Therefore, we propose GAS: a gloss-augmented WSD neural network which jointly encodes the context and glosses of the target word. GAS models the semantic relationship between the context and the gloss in an improved memory network framework, which breaks the barriers of the previous supervised methods and knowledge-based methods. We further extend the original gloss of word sense via its semantic relations in WordNet to enrich the gloss information. The experimental results show that our model outperforms the state-of-theart systems on several English all-words WSD datasets.
Improving Chinese SRL with Heterogeneous Annotations
Mar 14, 2017



Previous studies on Chinese semantic role labeling (SRL) have concentrated on single semantically annotated corpus. But the training data of single corpus is often limited. Meanwhile, there usually exists other semantically annotated corpora for Chinese SRL scattered across different annotation frameworks. Data sparsity remains a bottleneck. This situation calls for larger training datasets, or effective approaches which can take advantage of highly heterogeneous data. In these papers, we focus mainly on the latter, that is, to improve Chinese SRL by using heterogeneous corpora together. We propose a novel progressive learning model which augments the Progressive Neural Network with Gated Recurrent Adapters. The model can accommodate heterogeneous inputs and effectively transfer knowledge between them. We also release a new corpus, Chinese SemBank, for Chinese SRL. Experiments on CPB 1.0 show that ours model outperforms state-of-the-art methods.