 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Navigation with Language Pretraining and Stochastic Sampling
Paper and Code
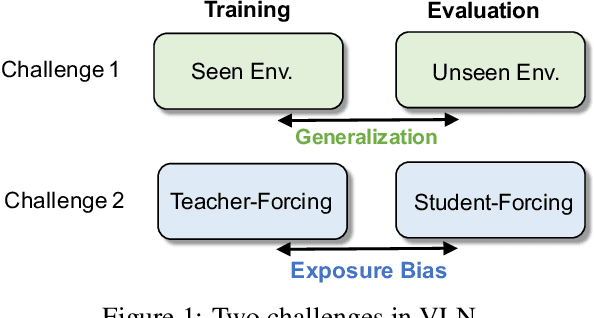
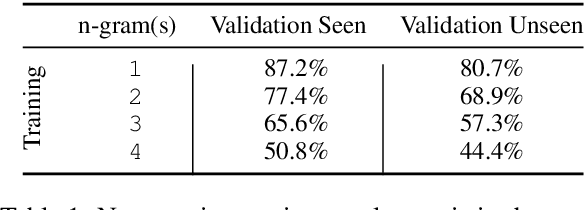
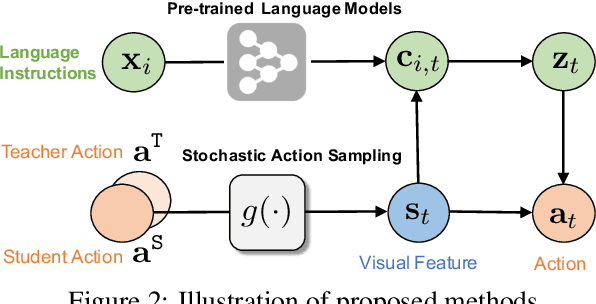
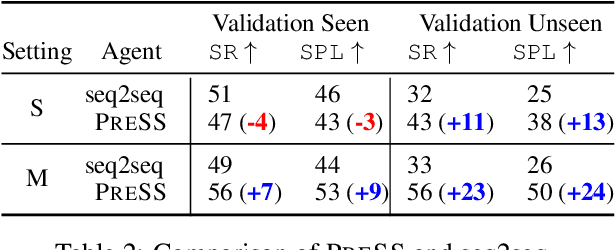
Core to the vision-and-language navigation (VLN) challenge is building robust instruction representations and action decoding schemes, which can generalize well to previously unseen instructions and environments. In this paper, we report two simple but highly effective methods to address these challenges and lead to a new state-of-the-art performance. First, we adapt large-scale pretrained language models to learn text representations that generalize better to previously unseen instructions. Second, we propose a stochastic sampling scheme to reduce the considerable gap between the expert actions in training and sampled actions in test, so that the agent can learn to correct its own mistakes during long sequential action decoding. Combining the two techniques, we achieve a new state of the art on the Room-to-Room benchmark with 6% absolute gain over the previous best result (47% -> 53%) on the Success Rate weighted by Path Length metric.