 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat are they talking about? Benchmarking Large Language Models for Knowledge-Grounded Discussion Summarization
May 18, 2025In this work, we investigate the performance of LLMs on a new task that requires combining discussion with background knowledge for summarization. This aims to address the limitation of outside observer confusion in existing dialogue summarization systems due to their reliance solely on discussion information. To achieve this, we model the task output as background and opinion summaries and define two standardized summarization patterns. To support assessment, we introduce the first benchmark comprising high-quality samples consistently annotated by human experts and propose a novel hierarchical evaluation framework with fine-grained, interpretable metrics. We evaluate 12 LLMs under structured-prompt and self-reflection paradigms. Our findings reveal: (1) LLMs struggle with background summary retrieval, generation, and opinion summary integration. (2) Even top LLMs achieve less than 69% average performance across both patterns. (3) Current LLMs lack adequate self-evaluation and self-correction capabilities for this task.
Multi-Stage Pre-training Enhanced by ChatGPT for Multi-Scenario Multi-Domain Dialogue Summarization
Oct 16, 2023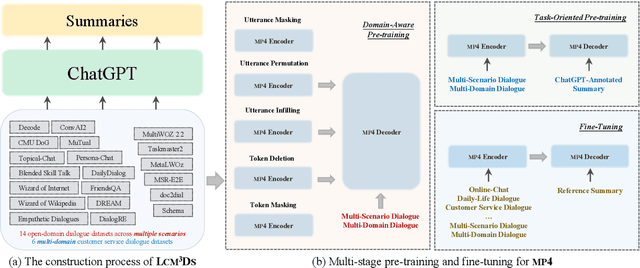

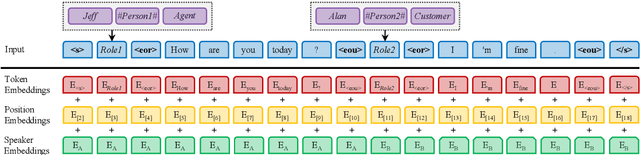
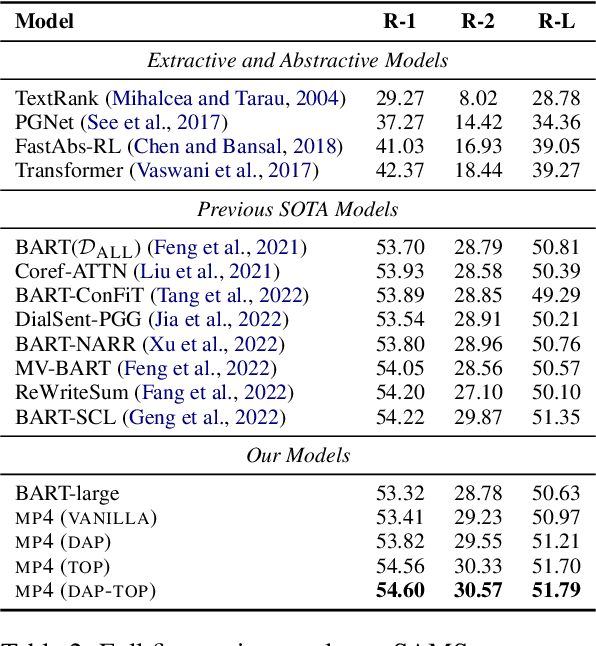
Dialogue summarization involves a wide range of scenarios and domains. However, existing methods generally only apply to specific scenarios or domains. In this study, we propose a new pre-trained model specifically designed for multi-scenario multi-domain dialogue summarization. It adopts a multi-stage pre-training strategy to reduce the gap between the pre-training objective and fine-tuning objective. Specifically, we first conduct domain-aware pre-training using large-scale multi-scenario multi-domain dialogue data to enhance the adaptability of our pre-trained model. Then, we conduct task-oriented pre-training using large-scale multi-scenario multi-domain "dialogue-summary" parallel data annotated by ChatGPT to enhance the dialogue summarization ability of our pre-trained model. Experimental results on three dialogue summarization datasets from different scenarios and domains indicate that our pre-trained model significantly outperforms previous state-of-the-art models in full fine-tuning, zero-shot, and few-shot settings.