 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAT: Dialogue-Aware Transformer with Modality-Group Fusion for Human Engagement Estimation
Paper and Code
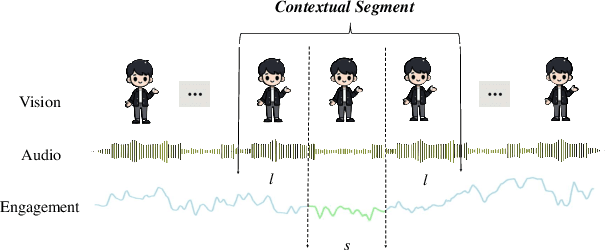
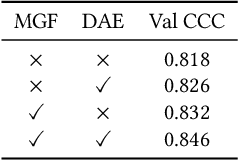
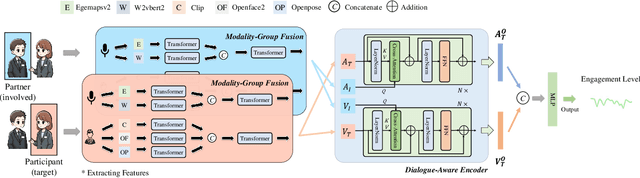

Engagement estimation plays a crucial role in understanding human social behaviors, attracting increasing research interests in fields such as affective computing and human-computer interaction. In this paper, we propose a Dialogue-Aware Transformer framework (DAT) with Modality-Group Fusion (MGF), which relies solely on audio-visual input and is language-independent, for estimating human engagement in conversations. Specifically, our method employs a modality-group fusion strategy that independently fuses audio and visual features within each modality for each person before inferring the entire audio-visual content. This strategy significantly enhances the model's performance and robustness. Additionally, to better estimate the target participant's engagement levels, the introduced Dialogue-Aware Transformer considers both the participant's behavior and cues from their conversational partners. Our method was rigorously tested in the Multi-Domain Engagement Estimation Challenge held by MultiMediate'24, demonstrating notable improvements in engagement-level regression precision over the baseline model. Notably, our approach achieves a CCC score of 0.76 on the NoXi Base test set and an average CCC of 0.64 across the NoXi Base, NoXi-Add, and MPIIGI test sets.