 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViRel: Unsupervised Visual Relations Discovery with Graph-level Analogy
Paper and Code
Jul 04, 2022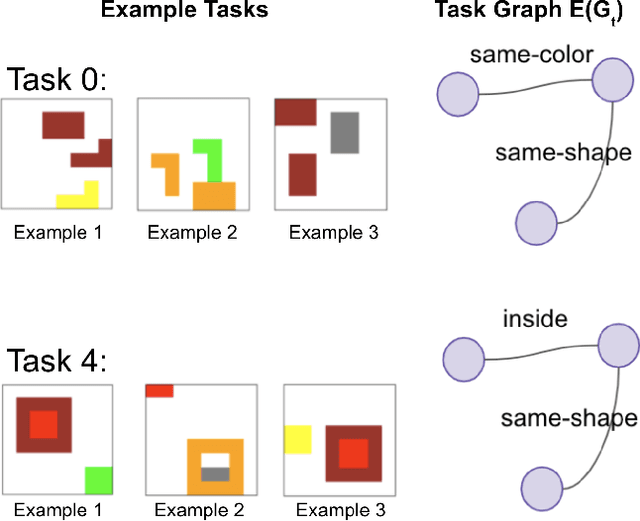

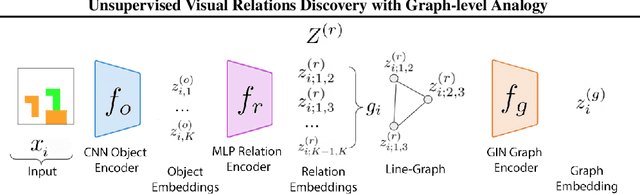
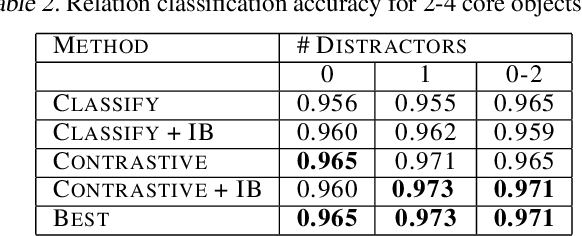
Visual relations form the basis of understanding our compositional world, as relationships between visual objects capture key information in a scene. It is then advantageous to learn relations automatically from the data, as learning with predefined labels cannot capture all possible relations. However, current relation learning methods typically require supervision, and are not designed to generalize to scenes with more complicated relational structures than those seen during training. Here, we introduce ViRel, a method for unsupervised discovery and learning of Visual Relations with graph-level analogy. In a setting where scenes within a task share the same underlying relational subgraph structure, our learning method of contrasting isomorphic and non-isomorphic graphs discovers the relations across tasks in an unsupervised manner. Once the relations are learned, ViRel can then retrieve the shared relational graph structure for each task by parsing the predicted relational structure. Using a dataset based on grid-world and the Abstract Reasoning Corpus, we show that our method achieves above 95% accuracy in relation classification, discovers the relation graph structure for most tasks, and further generalizes to unseen tasks with more complicated relational structures.