 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReason and Verify: A Framework for Faithful Retrieval-Augmented Generation
Mar 10, 2026Retrieval-Augmented Generation (RAG) significantly improves the factuality of Large Language Models (LLMs), yet standard pipelines often lack mechanisms to verify inter- mediate reasoning, leaving them vulnerable to hallucinations in high-stakes domains. To address this, we propose a domain-specific RAG framework that integrates explicit rea- soning and faithfulness verification. Our architecture augments standard retrieval with neural query rewriting, BGE-based cross-encoder reranking, and a rationale generation module that grounds sub-claims in specific evidence spans. We further introduce an eight-category verification taxonomy that enables fine-grained assessment of rationale faithfulness, distinguishing between explicit and implicit support patterns to facilitate structured error diagnosis. We evaluate this framework on the BioASQ and PubMedQA benchmarks, specifically analyzing the impact of dynamic in-context learning and rerank- ing under constrained token budgets. Experiments demonstrate that explicit rationale generation improves accuracy over vanilla RAG baselines, while dynamic demonstration selection combined with robust reranking yields further gains in few-shot settings. Using Llama-3-8B-Instruct, our approach achieves 89.1% on BioASQ-Y/N and 73.0% on Pub- MedQA, competitive with systems using significantly larger models. Additionally, we perform a pilot study combining human expert assessment with LLM-based verification to explore how explicit rationale generation improves system transparency and enables more detailed diagnosis of retrieval failures in biomedical question answering.
Quick Starting Dialog Systems with Paraphrase Generation
Apr 06, 2022

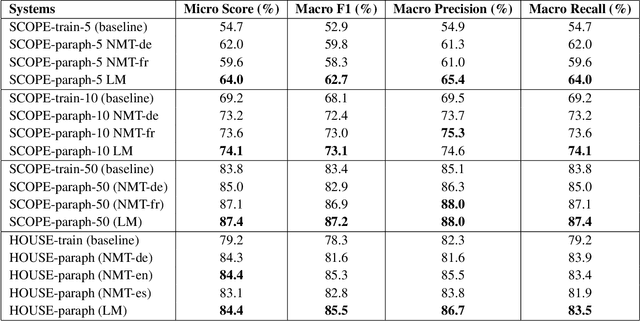
Acquiring training data to improve the robustness of dialog systems can be a painstakingly long process. In this work, we propose a method to reduce the cost and effort of creating new conversational agents by artificially generating more data from existing examples, using paraphrase generation. Our proposed approach can kick-start a dialog system with little human effort, and brings its performance to a level satisfactory enough for allowing actual interactions with real end-users. We experimented with two neural paraphrasing approaches, namely Neural Machine Translation and a Transformer-based seq2seq model. We present the results obtained with two datasets in English and in French:~a crowd-sourced public intent classification dataset and our own corporate dialog system dataset. We show that our proposed approach increased the generalization capabilities of the intent classification model on both datasets, reducing the effort required to initialize a new dialog system and helping to deploy this technology at scale within an organization.
Multi-stage Clarification in Conversational AI: The case of Question-Answering Dialogue Systems
Oct 28, 2021
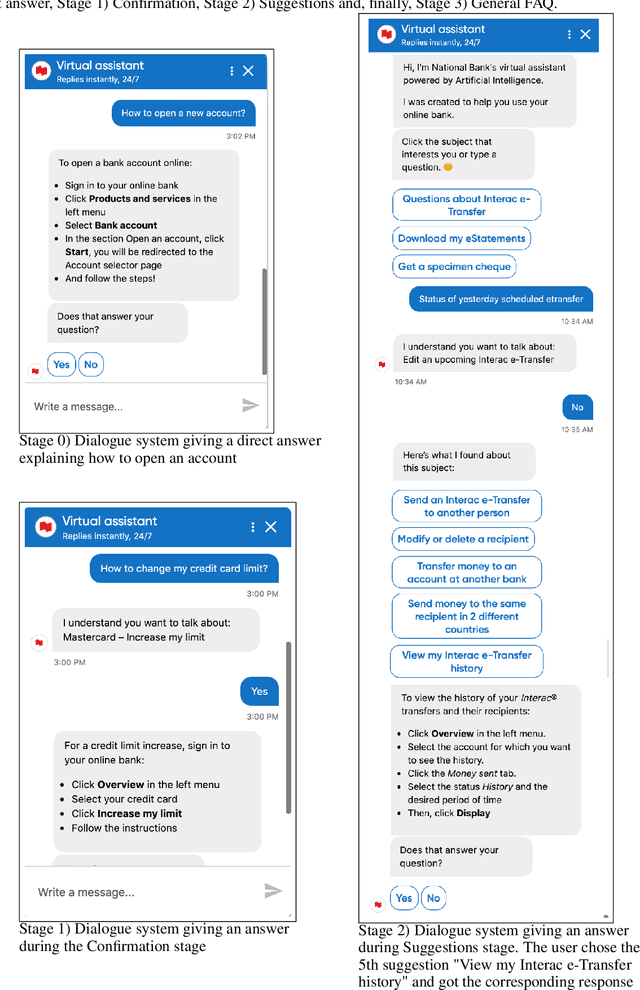
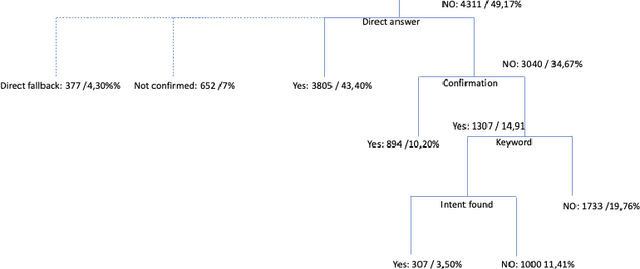

Clarification resolution plays an important role in various information retrieval tasks such as interactive question answering and conversational search. In such context, the user often formulates their information needs as short and ambiguous queries, some popular search interfaces then prompt the user to confirm her intent (e.g. "Did you mean ... ?") or to rephrase if needed. When it comes to dialogue systems, having fluid user-bot exchanges is key to good user experience. In the absence of such clarification mechanism, one of the following responses is given to the user: 1) A direct answer, which can potentially be non-relevant if the intent was not clear, 2) a generic fallback message informing the user that the retrieval tool is incapable of handling the query. Both scenarios might raise frustration and degrade the user experience. To this end, we propose a multi-stage clarification mechanism for prompting clarification and query selection in the context of a question answering dialogue system. We show that our proposed mechanism improves the overall user experience and outperforms competitive baselines with two datasets, namely the public in-scope out-of-scope dataset and a commercial dataset based on real user logs.
Inter and Intra Document Attention for Depression Risk Assessment
Jun 30, 2019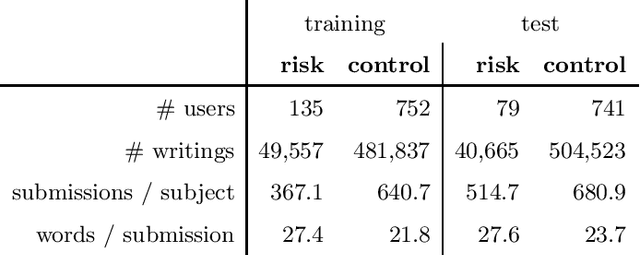
We take interest in the early assessment of risk for depression in social media users. We focus on the eRisk 2018 dataset, which represents users as a sequence of their written online contributions. We implement four RNN-based systems to classify the users. We explore several aggregations methods to combine predictions on individual posts. Our best model reads through all writings of a user in parallel but uses an attention mechanism to prioritize the most important ones at each timestep.