 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnited we stand, Divided we fall: Handling Weak Complementary Relationships for Audio-Visual Emotion Recognition in Valence-Arousal Space
Mar 21, 2025Audio and visual modalities are two predominant contact-free channels in videos, which are often expected to carry a complementary relationship with each other. However, they may not always complement each other, resulting in poor audio-visual feature representations. In this paper, we introduce Gated Recursive Joint Cross Attention (GRJCA) using a gating mechanism that can adaptively choose the most relevant features to effectively capture the synergic relationships across audio and visual modalities. Specifically, we improve the performance of Recursive Joint Cross-Attention (RJCA) by introducing a gating mechanism to control the flow of information between the input features and the attended features of multiple iterations depending on the strength of their complementary relationship. For instance, if the modalities exhibit strong complementary relationships, the gating mechanism emphasizes cross-attended features, otherwise non-attended features. To further improve the performance of the system, we also explored a hierarchical gating approach by introducing a gating mechanism at every iteration, followed by high-level gating across the gated outputs of each iteration. The proposed approach improves the performance of RJCA model by adding more flexibility to deal with weak complementary relationships across audio and visual modalities. Extensive experiments are conducted on the challenging Affwild2 dataset to demonstrate the robustness of the proposed approach. By effectively handling the weak complementary relationships across the audio and visual modalities, the proposed model achieves a Concordance Correlation Coefficient (CCC) of 0.561 (0.623) and 0.620 (0.660) for valence and arousal respectively on the test set (validation set).
Handling Weak Complementary Relationships for Audio-Visual Emotion Recognition
Mar 15, 2025Multimodal emotion recognition has recently drawn a lot of interest in affective computing as it has immense potential to outperform isolated unimodal approaches. Audio and visual modalities are two predominant contact-free channels in videos, which are often expected to carry a complementary relationship with each other. However, audio and visual channels may not always be complementary with each other, resulting in poor audio-visual feature representations, thereby degrading the performance of the system. In this paper, we propose a flexible audio-visual fusion model that can adapt to weak complementary relationships using a gated attention mechanism. Specifically, we extend the recursive joint cross-attention model by introducing gating mechanism in every iteration to control the flow of information between the input features and the attended features depending on the strength of their complementary relationship. For instance, if the modalities exhibit strong complementary relationships, the gating mechanism chooses cross-attended features, otherwise non-attended features. To further improve the performance of the system, we further introduce stage gating mechanism, which is used to control the flow of information across the gated outputs of each iteration. Therefore, the proposed model improves the performance of the system even when the audio and visual modalities do not have a strong complementary relationship with each other by adding more flexibility to the recursive joint cross attention mechanism. The proposed model has been evaluated on the challenging Affwild2 dataset and significantly outperforms the state-of-the-art fusion approaches.
Recursive Joint Cross-Modal Attention for Multimodal Fusion in Dimensional Emotion Recognition
Mar 30, 2024
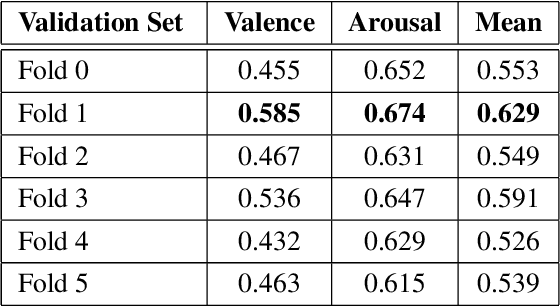
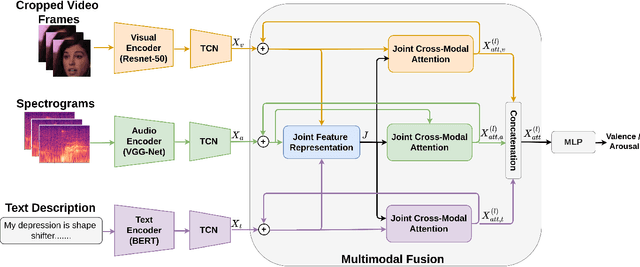
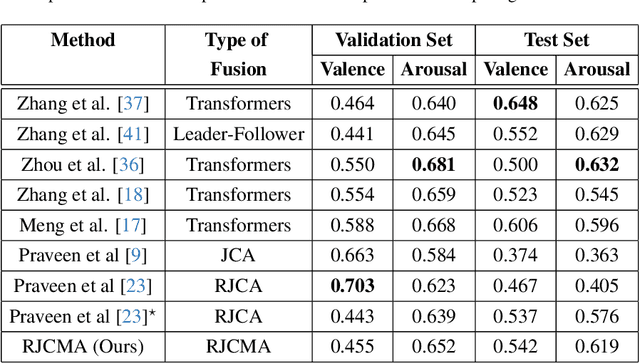
Though multimodal emotion recognition has achieved significant progress over recent years, the potential of rich synergic relationships across the modalities is not fully exploited. In this paper, we introduce Recursive Joint Cross-Modal Attention (RJCMA) to effectively capture both intra-and inter-modal relationships across audio, visual and text modalities for dimensional emotion recognition. In particular, we compute the attention weights based on cross-correlation between the joint audio-visual-text feature representations and the feature representations of individual modalities to simultaneously capture intra- and inter-modal relationships across the modalities. The attended features of the individual modalities are again fed as input to the fusion model in a recursive mechanism to obtain more refined feature representations. We have also explored Temporal Convolutional Networks (TCNs) to improve the temporal modeling of the feature representations of individual modalities. Extensive experiments are conducted to evaluate the performance of the proposed fusion model on the challenging Affwild2 dataset. By effectively capturing the synergic intra- and inter-modal relationships across audio, visual and text modalities, the proposed fusion model achieves a Concordance Correlation Coefficient (CCC) of 0.585 (0.542) and 0.659 (0.619) for valence and arousal respectively on the validation set (test set). This shows a significant improvement over the baseline of 0.24 (0.211) and 0.20 (0.191) for valence and arousal respectively on the validation set (test set) of the valence-arousal challenge of 6th Affective Behavior Analysis in-the-Wild (ABAW) competition.
Cross-Attention is Not Always Needed: Dynamic Cross-Attention for Audio-Visual Dimensional Emotion Recognition
Mar 28, 2024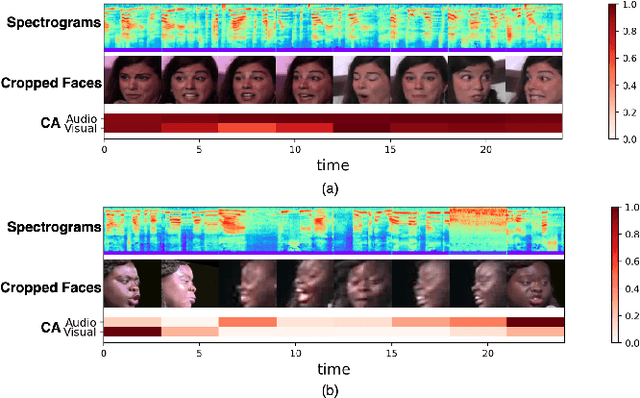
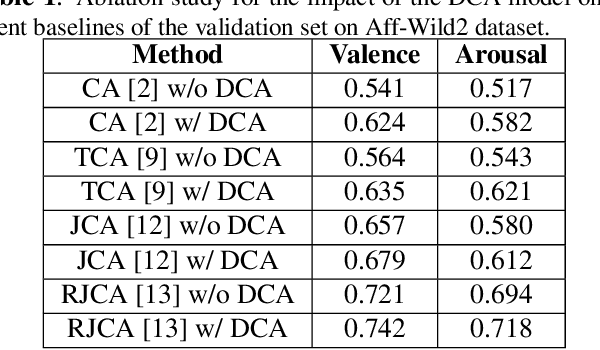
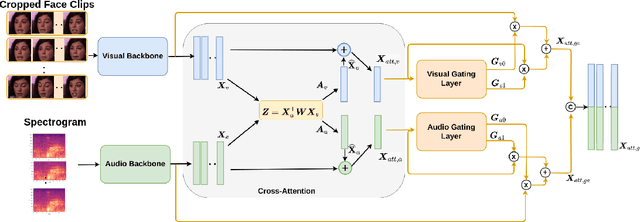
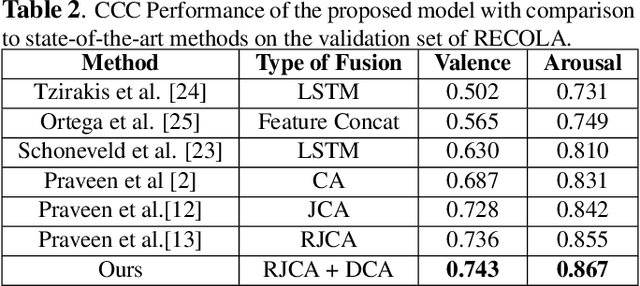
In video-based emotion recognition, audio and visual modalities are often expected to have a complementary relationship, which is widely explored using cross-attention. However, they may also exhibit weak complementary relationships, resulting in poor representations of audio-visual features, thus degrading the performance of the system. To address this issue, we propose Dynamic Cross-Attention (DCA) that can dynamically select cross-attended or unattended features on the fly based on their strong or weak complementary relationship with each other, respectively. Specifically, a simple yet efficient gating layer is designed to evaluate the contribution of the cross-attention mechanism and choose cross-attended features only when they exhibit a strong complementary relationship, otherwise unattended features. We evaluate the performance of the proposed approach on the challenging RECOLA and Aff-Wild2 datasets. We also compare the proposed approach with other variants of cross-attention and show that the proposed model consistently improves the performance on both datasets.
Audio-Visual Person Verification based on Recursive Fusion of Joint Cross-Attention
Mar 12, 2024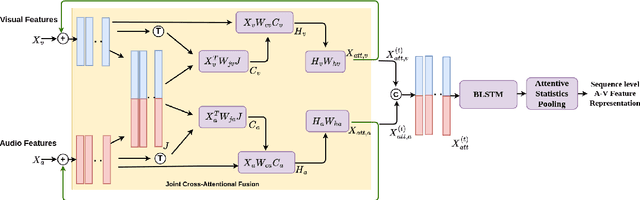
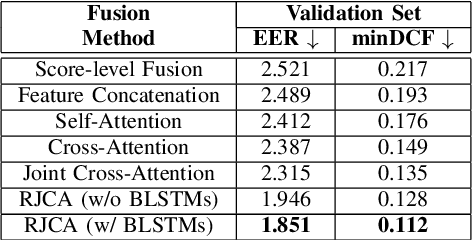

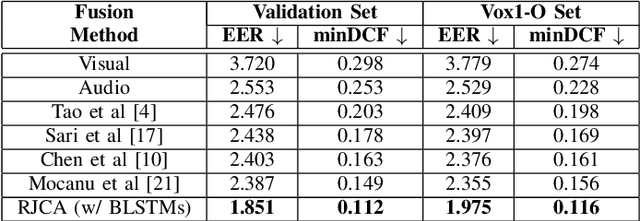
Person or identity verification has been recently gaining a lot of attention using audio-visual fusion as faces and voices share close associations with each other. Conventional approaches based on audio-visual fusion rely on score-level or early feature-level fusion techniques. Though existing approaches showed improvement over unimodal systems, the potential of audio-visual fusion for person verification is not fully exploited. In this paper, we have investigated the prospect of effectively capturing both the intra- and inter-modal relationships across audio and visual modalities, which can play a crucial role in significantly improving the fusion performance over unimodal systems. In particular, we introduce a recursive fusion of a joint cross-attentional model, where a joint audio-visual feature representation is employed in the cross-attention framework in a recursive fashion to progressively refine the feature representations that can efficiently capture the intra-and inter-modal relationships. To further enhance the audio-visual feature representations, we have also explored BLSTMs to improve the temporal modeling of audio-visual feature representations. Extensive experiments are conducted on the Voxceleb1 dataset to evaluate the proposed model. Results indicate that the proposed model shows promising improvement in fusion performance by adeptly capturing the intra-and inter-modal relationships across audio and visual modalities.
Dynamic Cross Attention for Audio-Visual Person Verification
Mar 12, 2024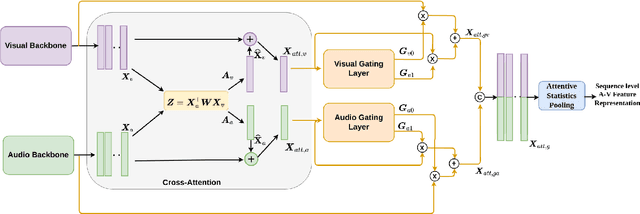
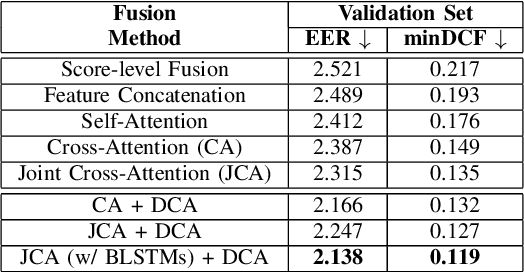
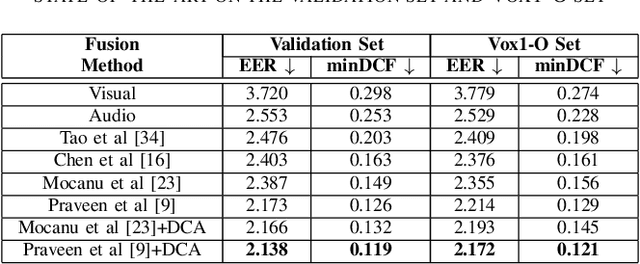
Although person or identity verification has been predominantly explored using individual modalities such as face and voice, audio-visual fusion has recently shown immense potential to outperform unimodal approaches. Audio and visual modalities are often expected to pose strong complementary relationships, which plays a crucial role in effective audio-visual fusion. However, they may not always strongly complement each other, they may also exhibit weak complementary relationships, resulting in poor audio-visual feature representations. In this paper, we propose a Dynamic Cross-Attention (DCA) model that can dynamically select the cross-attended or unattended features on the fly based on the strong or weak complementary relationships, respectively, across audio and visual modalities. In particular, a conditional gating layer is designed to evaluate the contribution of the cross-attention mechanism and choose cross-attended features only when they exhibit strong complementary relationships, otherwise unattended features. Extensive experiments are conducted on the Voxceleb1 dataset to demonstrate the robustness of the proposed model. Results indicate that the proposed model consistently improves the performance on multiple variants of cross-attention while outperforming the state-of-the-art methods.
Audio-Visual Speaker Verification via Joint Cross-Attention
Sep 28, 2023

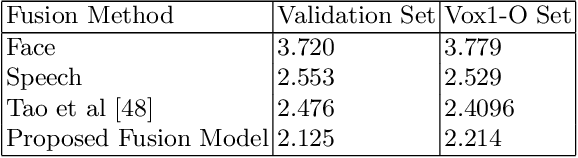
Speaker verification has been widely explored using speech signals, which has shown significant improvement using deep models. Recently, there has been a surge in exploring faces and voices as they can offer more complementary and comprehensive information than relying only on a single modality of speech signals. Though current methods in the literature on the fusion of faces and voices have shown improvement over that of individual face or voice modalities, the potential of audio-visual fusion is not fully explored for speaker verification. Most of the existing methods based on audio-visual fusion either rely on score-level fusion or simple feature concatenation. In this work, we have explored cross-modal joint attention to fully leverage the inter-modal complementary information and the intra-modal information for speaker verification. Specifically, we estimate the cross-attention weights based on the correlation between the joint feature presentation and that of the individual feature representations in order to effectively capture both intra-modal as well inter-modal relationships among the faces and voices. We have shown that efficiently leveraging the intra- and inter-modal relationships significantly improves the performance of audio-visual fusion for speaker verification. The performance of the proposed approach has been evaluated on the Voxceleb1 dataset. Results show that the proposed approach can significantly outperform the state-of-the-art methods of audio-visual fusion for speaker verification.