 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comparison of Deep Learning performances with others machine learning algorithms on credit scoring unbalanced data
Jul 25, 2019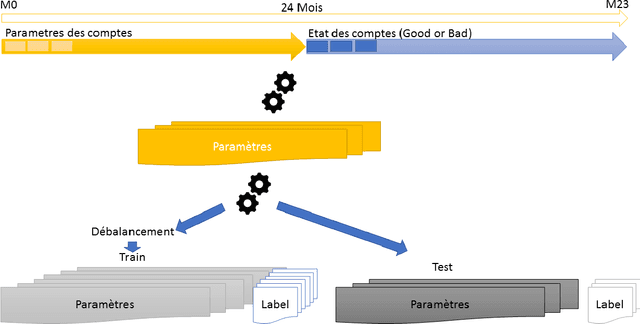
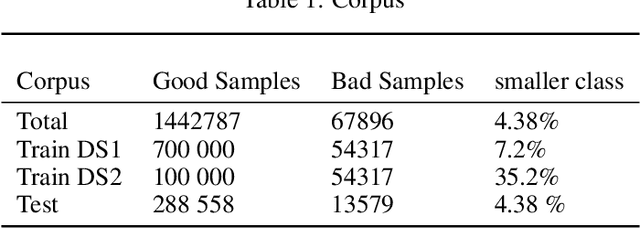
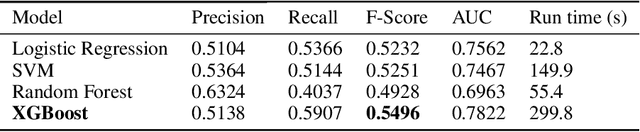
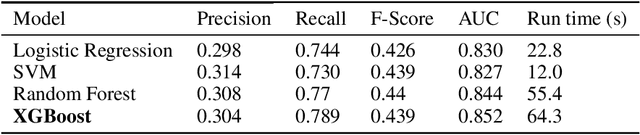
Training models on highly unbalanced data is admitted to be a challenging task for machine learning algorithms. Current studies on deep learning mainly focus on data sets with balanced class labels, or unbalanced data but with massive amount of samples available, like in speech recognition. However, the capacities of deep learning on imbalanced data with little samples is not deeply investigated in literature, while it is a very common application context, in numerous industries. To contribute to fill this gap, this paper compares the performances of several popular machine learning algorithms previously applied with success to unbalanced data set with deep learning algorithms. We conduct those experiments on an highly unbalanced data set, used for credit scoring. We evaluate various configuration including neural network optimisation techniques and try to determine their capacities when they operate with imbalanced corpora.