 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Iterative Contextualization Algorithm with Second-Order Attention
Paper and Code
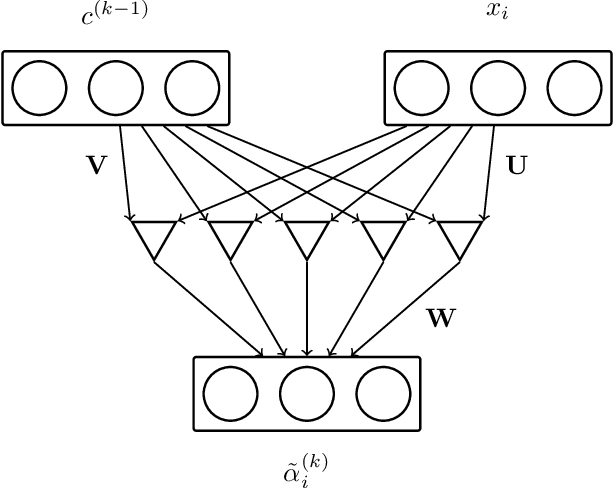
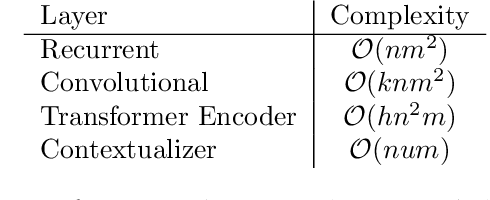

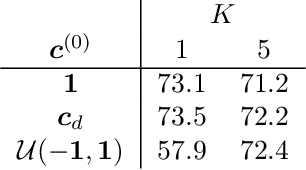
Combining the representations of the words that make up a sentence into a cohesive whole is difficult, since it needs to account for the order of words, and to establish how the words present relate to each other. The solution we propose consists in iteratively adjusting the context. Our algorithm starts with a presumably erroneous value of the context, and adjusts this value with respect to the tokens at hand. In order to achieve this, representations of words are built combining their symbolic embedding with a positional encoding into single vectors. The algorithm then iteratively weighs and aggregates these vectors using our novel second-order attention mechanism. Our models report strong results in several well-known text classification tasks.