 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey of Computational Approaches to Diachronic Conceptual Change
Nov 15, 2018
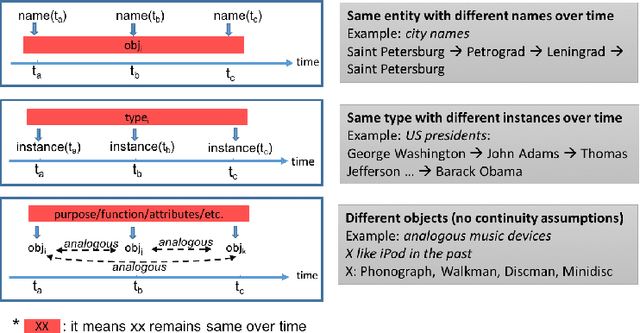


Our languages are in constant flux driven by external factors such as cultural, societal and technological changes, as well as by only partially understood internal motivations. Words acquire new meanings and lose old senses, new words are coined or borrowed from other languages and obsolete words slide into obscurity. Understanding the characteristics of shifts in the meaning and in the use of words is useful for those who work with the content of historical texts, the interested general public, but also in and of itself. The findings from automatic lexical semantic change detection, and the models of diachronic conceptual change are currently being incorporated in approaches for measuring document across-time similarity, information retrieval from long-term document archives, the design of OCR algorithms, and so on. In recent years we have seen a surge in interest in the academic community in computational methods and tools supporting inquiry into diachronic conceptual change and lexical replacement. This article is an extract of a survey of recent computational techniques to tackle lexical semantic change currently under review. In this article we focus on diachronic conceptual change as an extension of semantic change.
Candidate sentence selection for language learning exercises: from a comprehensive framework to an empirical evaluation
Jun 12, 2017
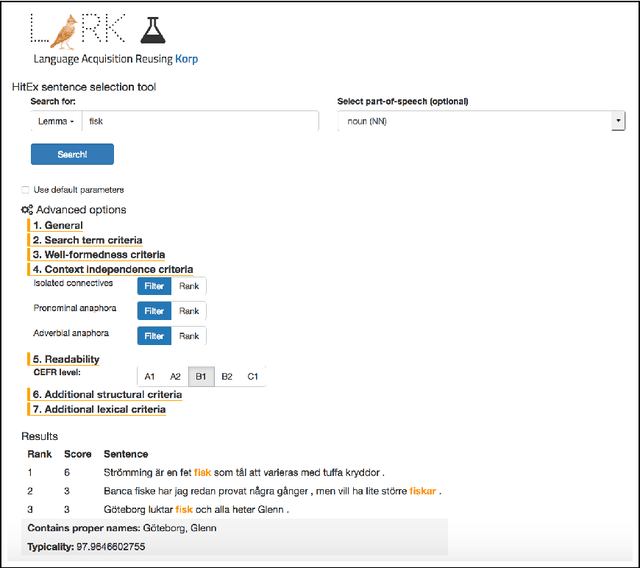
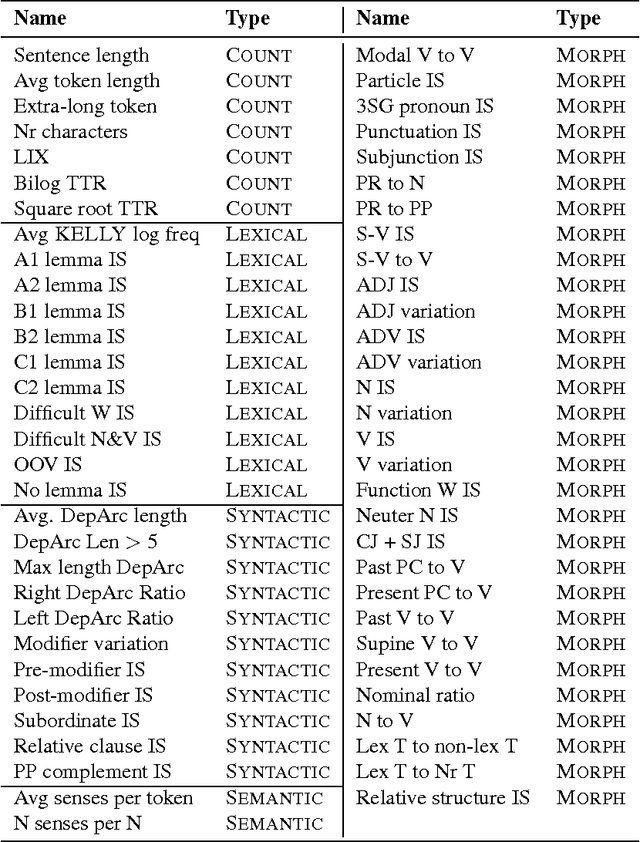

We present a framework and its implementation relying on Natural Language Processing methods, which aims at the identification of exercise item candidates from corpora. The hybrid system combining heuristics and machine learning methods includes a number of relevant selection criteria. We focus on two fundamental aspects: linguistic complexity and the dependence of the extracted sentences on their original context. Previous work on exercise generation addressed these two criteria only to a limited extent, and a refined overall candidate sentence selection framework appears also to be lacking. In addition to a detailed description of the system, we present the results of an empirical evaluation conducted with language teachers and learners which indicate the usefulness of the system for educational purposes. We have integrated our system into a freely available online learning platform.
Properties of phoneme N -grams across the world's language families
Jan 04, 2014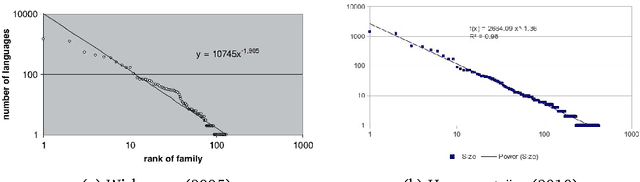

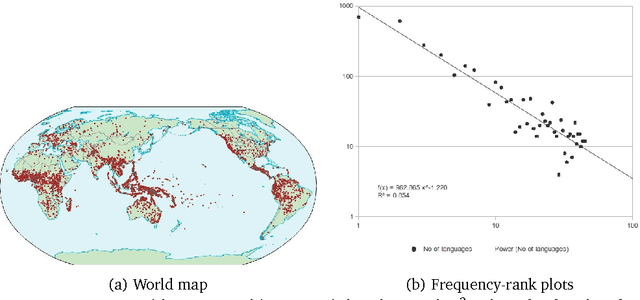
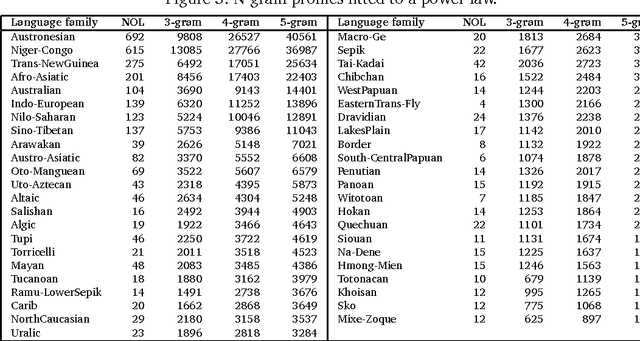
In this article, we investigate the properties of phoneme N-grams across half of the world's languages. We investigate if the sizes of three different N-gram distributions of the world's language families obey a power law. Further, the N-gram distributions of language families parallel the sizes of the families, which seem to obey a power law distribution. The correlation between N-gram distributions and language family sizes improves with increasing values of N. We applied statistical tests, originally given by physicists, to test the hypothesis of power law fit to twelve different datasets. The study also raises some new questions about the use of N-gram distributions in linguistic research, which we answer by running a statistical test.