 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemCSE: Semantic Contrastive Sentence Embeddings Using LLM-Generated Summaries For Scientific Abstracts
Jul 17, 2025
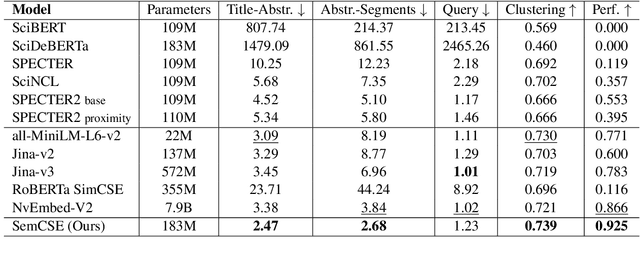


We introduce SemCSE, an unsupervised method for learning semantic embeddings of scientific texts. Building on recent advances in contrastive learning for text embeddings, our approach leverages LLM-generated summaries of scientific abstracts to train a model that positions semantically related summaries closer together in the embedding space. This resulting objective ensures that the model captures the true semantic content of a text, in contrast to traditional citation-based approaches that do not necessarily reflect semantic similarity. To validate this, we propose a novel benchmark designed to assess a model's ability to understand and encode the semantic content of scientific texts, demonstrating that our method enforces a stronger semantic separation within the embedding space. Additionally, we evaluate SemCSE on the comprehensive SciRepEval benchmark for scientific text embeddings, where it achieves state-of-the-art performance among models of its size, thus highlighting the benefits of a semantically focused training approach.
Enhancing Domain-Specific Encoder Models with LLM-Generated Data: How to Leverage Ontologies, and How to Do Without Them
Mar 27, 2025

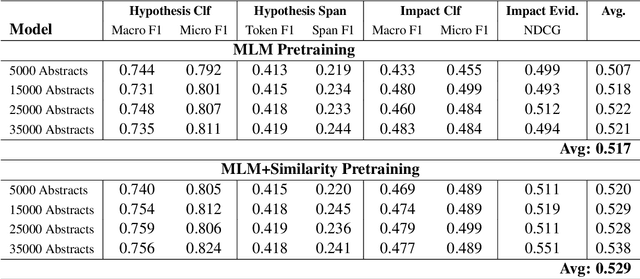
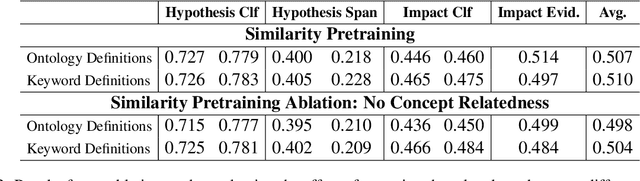
We investigate the use of LLM-generated data for continual pretraining of encoder models in specialized domains with limited training data, using the scientific domain of invasion biology as a case study. To this end, we leverage domain-specific ontologies by enriching them with LLM-generated data and pretraining the encoder model as an ontology-informed embedding model for concept definitions. To evaluate the effectiveness of this method, we compile a benchmark specifically designed for assessing model performance in invasion biology. After demonstrating substantial improvements over standard LLM pretraining, we investigate the feasibility of applying the proposed approach to domains without comprehensive ontologies by substituting ontological concepts with concepts automatically extracted from a small corpus of scientific abstracts and establishing relationships between concepts through distributional statistics. Our results demonstrate that this automated approach achieves comparable performance using only a small set of scientific abstracts, resulting in a fully automated pipeline for enhancing domain-specific understanding of small encoder models that is especially suited for application in low-resource settings and achieves performance comparable to masked language modeling pretraining on much larger datasets.