 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAdeML: Understanding the Impact of Pre-Processing Noise Filtering on Adversarial Machine Learning
Nov 04, 2018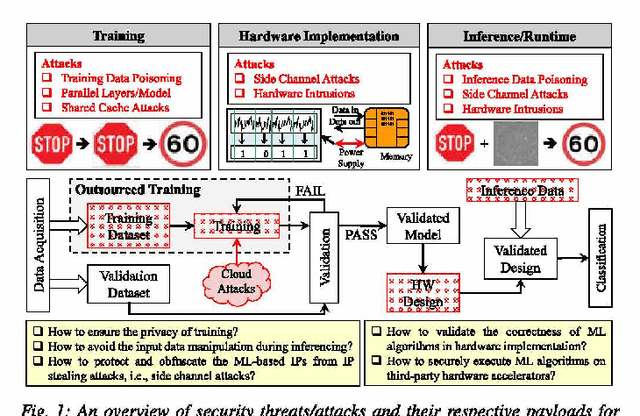
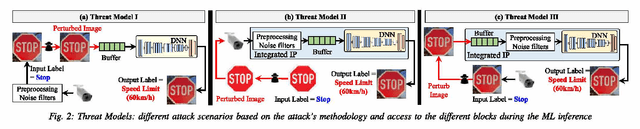
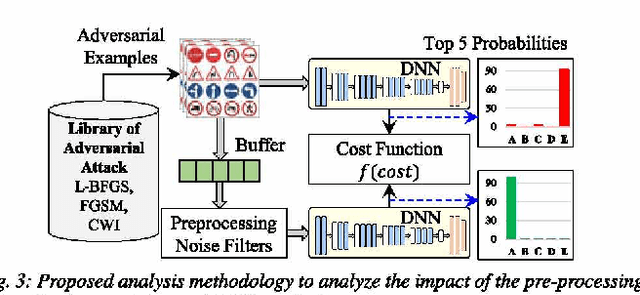
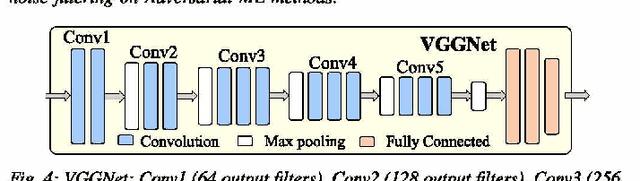
Deep neural networks (DNN)-based machine learning (ML) algorithms have recently emerged as the leading ML paradigm particularly for the task of classification due to their superior capability of learning efficiently from large datasets. The discovery of a number of well-known attacks such as dataset poisoning, adversarial examples, and network manipulation (through the addition of malicious nodes) has, however, put the spotlight squarely on the lack of security in DNN-based ML systems. In particular, malicious actors can use these well-known attacks to cause random/targeted misclassification, or cause a change in the prediction confidence, by only slightly but systematically manipulating the environmental parameters, inference data, or the data acquisition block. Most of the prior adversarial attacks have, however, not accounted for the pre-processing noise filters commonly integrated with the ML-inference module. Our contribution in this work is to show that this is a major omission since these noise filters can render ineffective the majority of the existing attacks, which rely essentially on introducing adversarial noise. Apart from this, we also extend the state of the art by proposing a novel pre-processing noise Filter-aware Adversarial ML attack called FAdeML. To demonstrate the effectiveness of the proposed methodology, we generate an adversarial attack image by exploiting the "VGGNet" DNN trained for the "German Traffic Sign Recognition Benchmarks (GTSRB" dataset, which despite having no visual noise, can cause a classifier to misclassify even in the presence of pre-processing noise filters.