 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeISA4ML: Training Data-Unaware Imperceptible Security Attacks on Machine Learning Modules of Autonomous Vehicles
Paper and Code
Nov 02, 2018
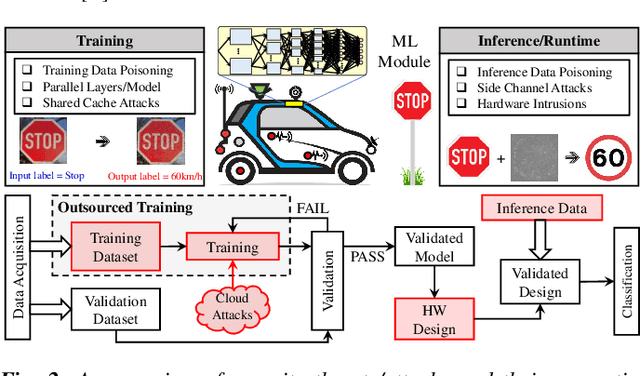


Due to big data analysis ability, machine learning (ML) algorithms are becoming popular for several applications in autonomous vehicles. However, ML algorithms possessinherent security vulnerabilities which increase the demand for robust ML algorithms. Recently, various groups have demonstrated how vulnerabilities in ML can be exploited to perform several security attacks for confidence reduction and random/targeted misclassification, by using the data manipulation techniques. These traditional data manipulation techniques, especially during the training stage, introduce the random visual noise. However, such visual noise can be detected during the attack or testing through noise detection/filtering or human-in-the-loop. In this paper, we propose a novel methodology to automatically generate an "imperceptible attack" by exploiting the back-propagation property of trained deep neural networks (DNNs). Unlike state-of-the-art inference attacks, our methodology does not require any knowledge of the training data set during the attack image generation. To illustrate the effectiveness of the proposed methodology, we present a case study for traffic sign detection in an autonomous driving use case. We deploy the state-of-the-art VGGNet DNN trained for German Traffic Sign Recognition Benchmarks (GTSRB) datasets. Our experimental results show that the generated attacks are imperceptible in both subjective tests (i.e., visual perception) and objective tests (i.e., without any noticeable change in the correlation and structural similarity index) but still performs successful misclassification attacks.