 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoll-Drop: accounting for observation noise with a single parameter
Apr 25, 2023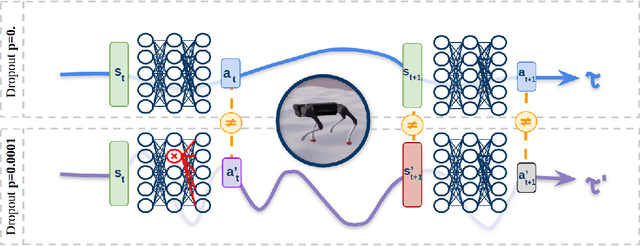

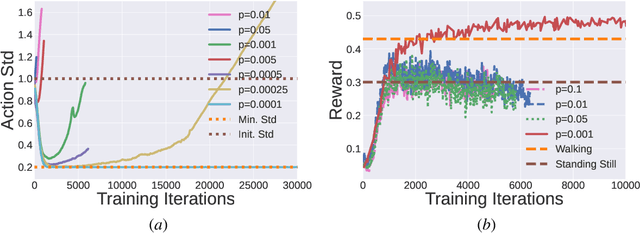
This paper proposes a simple strategy for sim-to-real in Deep-Reinforcement Learning (DRL) -- called Roll-Drop -- that uses dropout during simulation to account for observation noise during deployment without explicitly modelling its distribution for each state. DRL is a promising approach to control robots for highly dynamic and feedback-based manoeuvres, and accurate simulators are crucial to providing cheap and abundant data to learn the desired behaviour. Nevertheless, the simulated data are noiseless and generally show a distributional shift that challenges the deployment on real machines where sensor readings are affected by noise. The standard solution is modelling the latter and injecting it during training; while this requires a thorough system identification, Roll-Drop enhances the robustness to sensor noise by tuning only a single parameter. We demonstrate an 80% success rate when up to 25% noise is injected in the observations, with twice higher robustness than the baselines. We deploy the controller trained in simulation on a Unitree A1 platform and assess this improved robustness on the physical system.
Learning Low-Frequency Motion Control for Robust and Dynamic Robot Locomotion
Sep 29, 2022
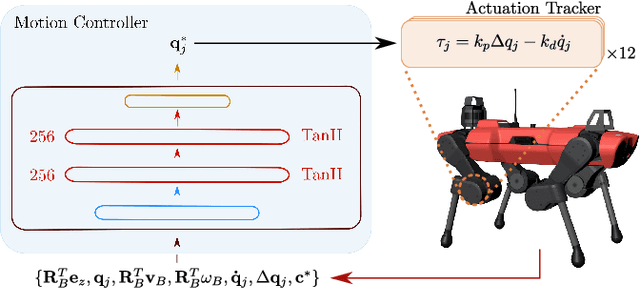
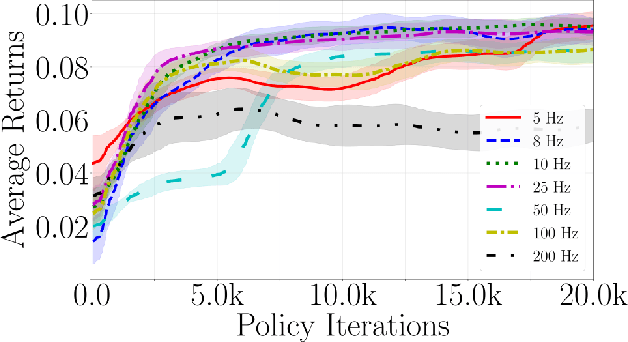

Robotic locomotion is often approached with the goal of maximizing robustness and reactivity by increasing motion control frequency. We challenge this intuitive notion by demonstrating robust and dynamic locomotion with a learned motion controller executing at as low as 8 Hz on a real ANYmal C quadruped. The robot is able to robustly and repeatably achieve a high heading velocity of 1.5 m/s, traverse uneven terrain, and resist unexpected external perturbations. We further present a comparative analysis of deep reinforcement learning (RL) based motion control policies trained and executed at frequencies ranging from 5 Hz to 200 Hz. We show that low-frequency policies are less sensitive to actuation latencies and variations in system dynamics. This is to the extent that a successful sim-to-real transfer can be performed even without any dynamics randomization or actuation modeling. We support this claim through a set of rigorous empirical evaluations. Moreover, to assist reproducibility, we provide the training and deployment code along with an extended analysis at https://ori-drs.github.io/lfmc/.
Learning and Deploying Robust Locomotion Policies with Minimal Dynamics Randomization
Sep 26, 2022
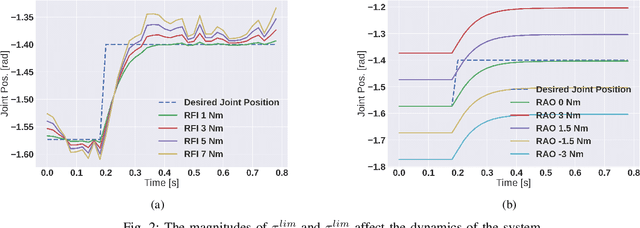

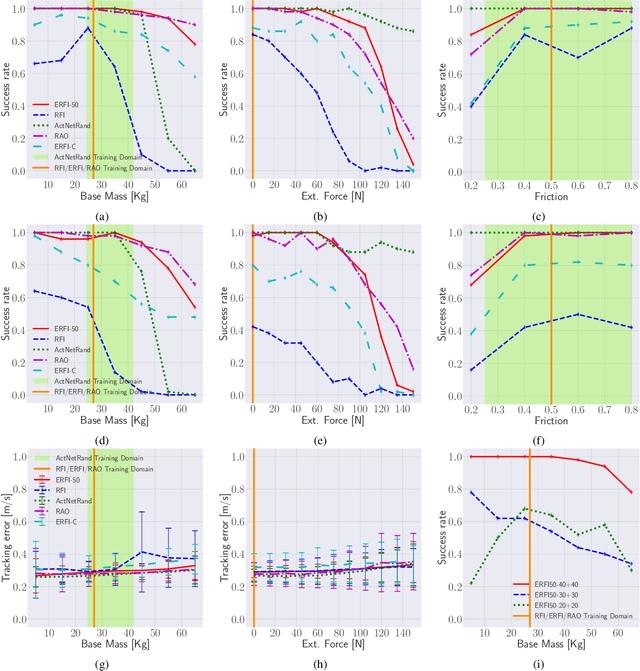
Training deep reinforcement learning (DRL) locomotion policies often requires massive amounts of data to converge to the desired behavior. In this regard, simulators provide a cheap and abundant source. For successful sim-to-real transfer, exhaustively engineered approaches such as system identification, dynamics randomization, and domain adaptation are generally employed. As an alternative, we investigate a simple strategy of random force injection (RFI) to perturb system dynamics during training. We show that the application of random forces enables us to emulate dynamics randomization.This allows us to obtain locomotion policies that are robust to variations in system dynamics. We further extend RFI, referred to as extended random force injection (ERFI), by introducing an episodic actuation offset. We demonstrate that ERFI provides additional robustness for variations in system mass offering on average a 61% improved performance over RFI. We also show that ERFI is sufficient to perform a successful sim-to-real transfer on two different quadrupedal platforms, ANYmal C and Unitree A1, even for perceptive locomotion over uneven terrain in outdoor environments.
CPG-ACTOR: Reinforcement Learning for Central Pattern Generators
Feb 25, 2021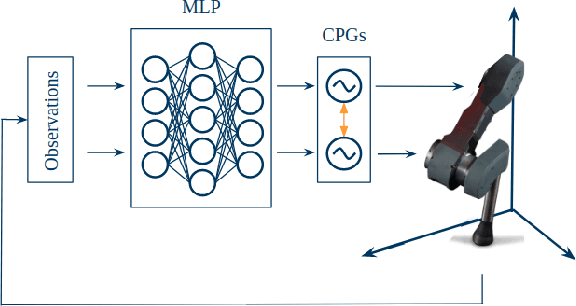
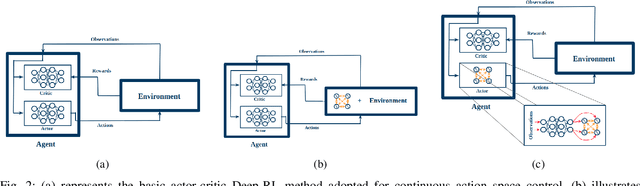
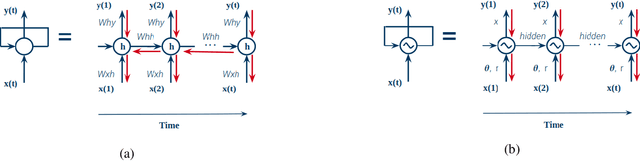
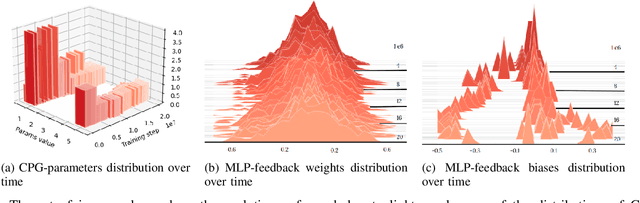
Central Pattern Generators (CPGs) have several properties desirable for locomotion: they generate smooth trajectories, are robust to perturbations and are simple to implement. Although conceptually promising, we argue that the full potential of CPGs has so far been limited by insufficient sensory-feedback information. This paper proposes a new methodology that allows tuning CPG controllers through gradient-based optimization in a Reinforcement Learning (RL) setting. To the best of our knowledge, this is the first time CPGs have been trained in conjunction with a MultilayerPerceptron (MLP) network in a Deep-RL context. In particular, we show how CPGs can directly be integrated as the Actor in an Actor-Critic formulation. Additionally, we demonstrate how this change permits us to integrate highly non-linear feedback directly from sensory perception to reshape the oscillators' dynamics. Our results on a locomotion task using a single-leg hopper demonstrate that explicitly using the CPG as the Actor rather than as part of the environment results in a significant increase in the reward gained over time (6x more) compared with previous approaches. Furthermore, we show that our method without feedback reproduces results similar to prior work with feedback. Finally, we demonstrate how our closed-loop CPG progressively improves the hopping behaviour for longer training epochs relying only on basic reward functions.