 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPG-ACTOR: Reinforcement Learning for Central Pattern Generators
Paper and Code
Feb 25, 2021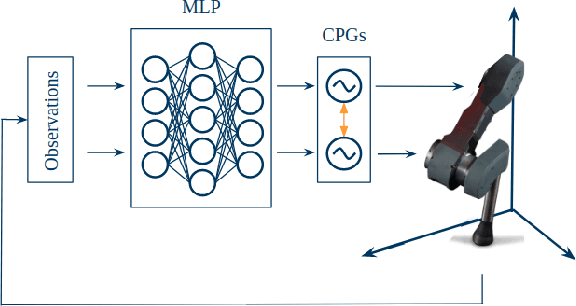
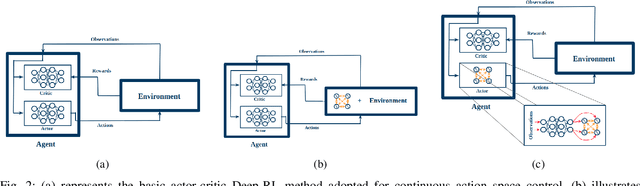
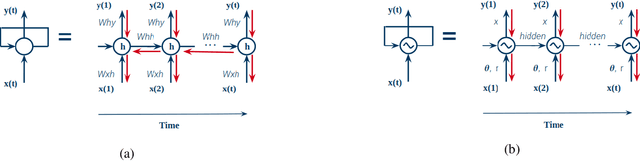
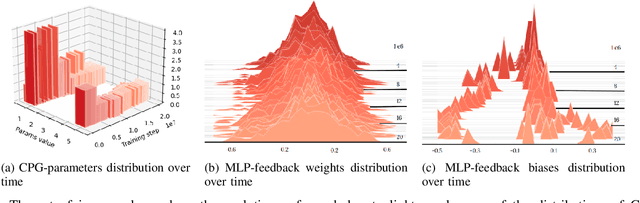
Central Pattern Generators (CPGs) have several properties desirable for locomotion: they generate smooth trajectories, are robust to perturbations and are simple to implement. Although conceptually promising, we argue that the full potential of CPGs has so far been limited by insufficient sensory-feedback information. This paper proposes a new methodology that allows tuning CPG controllers through gradient-based optimization in a Reinforcement Learning (RL) setting. To the best of our knowledge, this is the first time CPGs have been trained in conjunction with a MultilayerPerceptron (MLP) network in a Deep-RL context. In particular, we show how CPGs can directly be integrated as the Actor in an Actor-Critic formulation. Additionally, we demonstrate how this change permits us to integrate highly non-linear feedback directly from sensory perception to reshape the oscillators' dynamics. Our results on a locomotion task using a single-leg hopper demonstrate that explicitly using the CPG as the Actor rather than as part of the environment results in a significant increase in the reward gained over time (6x more) compared with previous approaches. Furthermore, we show that our method without feedback reproduces results similar to prior work with feedback. Finally, we demonstrate how our closed-loop CPG progressively improves the hopping behaviour for longer training epochs relying only on basic reward functions.