 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReaching, Grasping and Re-grasping: Learning Multimode Grasping Skills
Paper and Code
Feb 28, 2020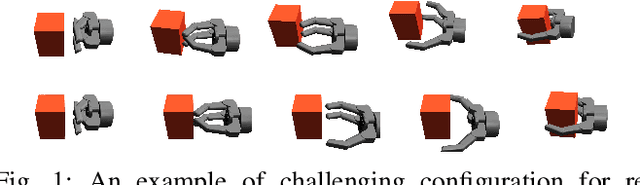
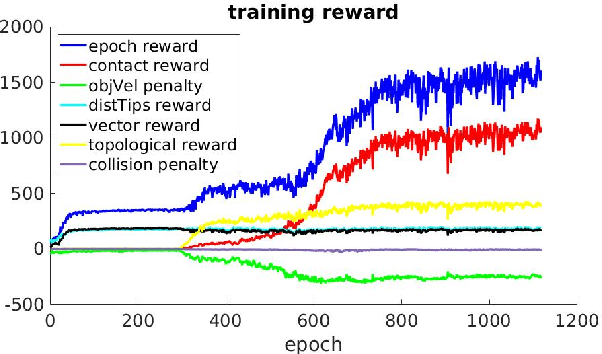
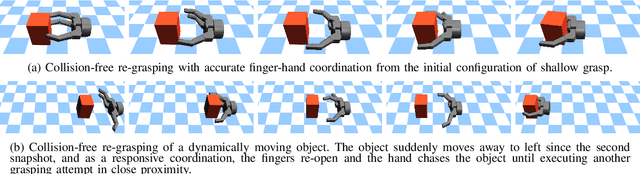
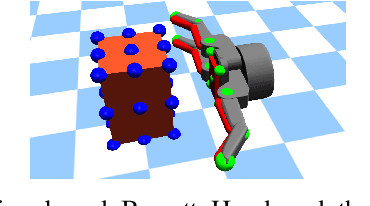
The ability to adapt to uncertainties, recover from failures, and coordinate between hand and fingers are essential sensorimotor skills for fully autonomous robotic grasping. In this paper, we aim to study a unified feedback control policy for generating the finger actions and the motion of hand to accomplish seamlessly coordinated tasks of reaching, grasping and re-grasping. We proposed a set of quantified metrics for task-orientated rewards to guide the policy exploration, and we analyzed and demonstrated the effectiveness of each reward term. To acquire a robust re-grasping motion, we deployed different initial states in training to experience failures that the robot would encounter during grasping due to inaccurate perception or disturbances. The performance of learned policy is evaluated on three different tasks: grasping a static target, grasping a dynamic target, and re-grasping. The quality of learned grasping policy was evaluated based on success rates in different scenarios and the recovery time from failures. The results indicate that the learned policy is able to achieve stable grasps of a static or moving object. Moreover, the policy can adapt to new environmental changes on the fly and execute collision-free re-grasp after a failed attempt within a short recovery time even in difficult configurations.