 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Deterministic Policy Gradient Method for Bipedal Locomotion on Rough Terrain Challenge
Sep 13, 2018
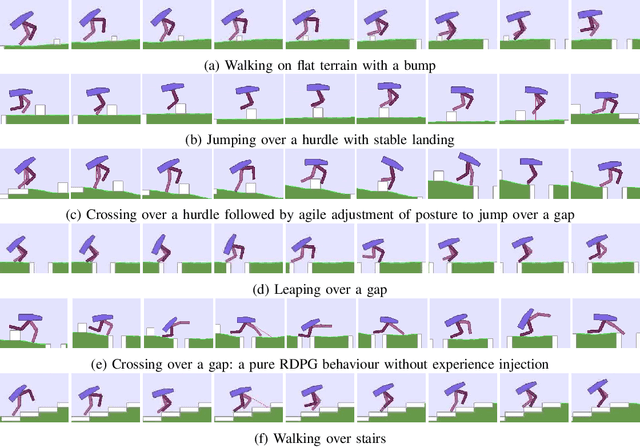

This paper presents a deep learning framework that is capable of solving partially observable locomotion tasks based on our novel interpretation of Recurrent Deterministic Policy Gradient (RDPG). We study on bias of sampled error measure and its variance induced by the partial observability of environment and subtrajectory sampling, respectively. Three major improvements are introduced in our RDPG based learning framework: tail-step bootstrap of interpolated temporal difference, initialisation of hidden state using past trajectory scanning, and injection of external experiences learned by other agents. The proposed learning framework was implemented to solve the Bipedal-Walker challenge in OpenAI's gym simulation environment where only partial state information is available. Our simulation study shows that the autonomous behaviors generated by the RDPG agent are highly adaptive to a variety of obstacles and enables the agent to effectively traverse rugged terrains for long distance with higher success rate than leading contenders.