 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpportunities and Challenges in Deep Learning Adversarial Robustness: A Survey
Paper and Code
Jul 03, 2020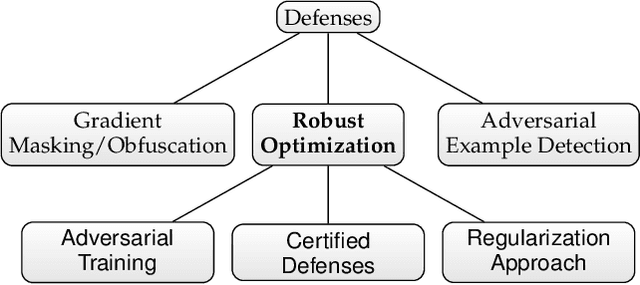
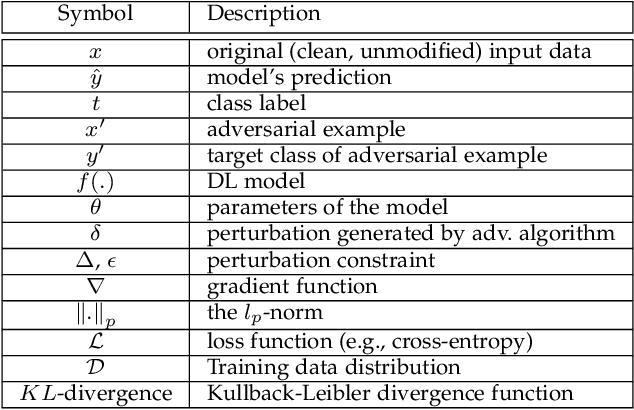
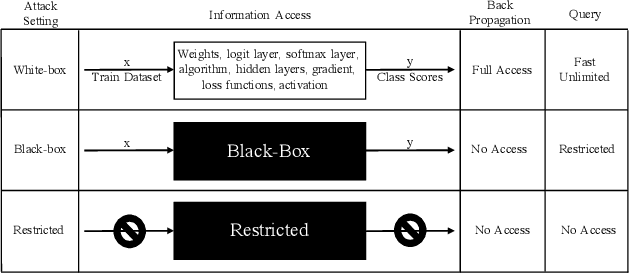
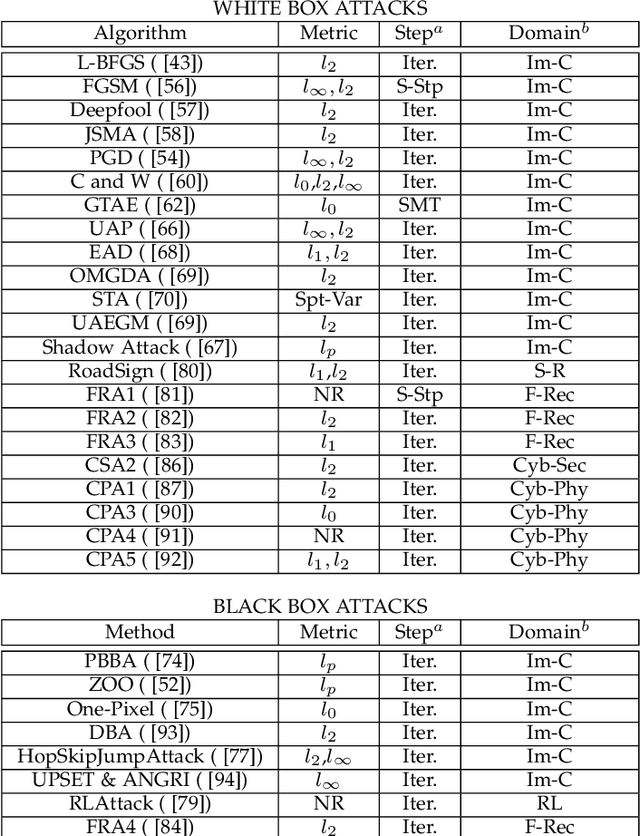
As we seek to deploy machine learning models beyond virtual and controlled domains, it is critical to analyze not only the accuracy or the fact that it works most of the time, but if such a model is truly robust and reliable. This paper studies strategies to implement adversary robustly trained algorithms towards guaranteeing safety in machine learning algorithms. We provide a taxonomy to classify adversarial attacks and defenses, formulate the Robust Optimization problem in a min-max setting and divide it into 3 subcategories, namely: Adversarial (re)Training, Regularization Approach, and Certified Defenses. We survey the most recent and important results in adversarial example generation, defense mechanisms with adversarial (re)Training as their main defense against perturbations. We also survey mothods that add regularization terms that change the behavior of the gradient, making it harder for attackers to achieve their objective. Alternatively, we've surveyed methods which formally derive certificates of robustness by exactly solving the optimization problem or by approximations using upper or lower bounds. In addition, we discuss the challenges faced by most of the recent algorithms presenting future research perspectives.