 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIPeR: Provably Efficient Algorithm for Offline RL with Neural Function Approximation
Paper and Code



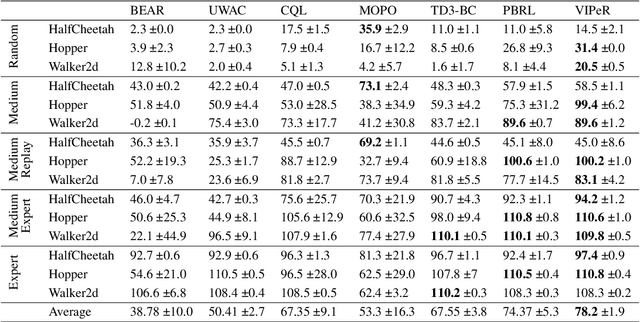
We propose a novel algorithm for offline reinforcement learning called Value Iteration with Perturbed Rewards (VIPeR), which amalgamates the pessimism principle with random perturbations of the value function. Most current offline RL algorithms explicitly construct statistical confidence regions to obtain pessimism via lower confidence bounds (LCB), which cannot easily scale to complex problems where a neural network is used to estimate the value functions. Instead, VIPeR implicitly obtains pessimism by simply perturbing the offline data multiple times with carefully-designed i.i.d. Gaussian noises to learn an ensemble of estimated state-action {value functions} and acting greedily with respect to the minimum of the ensemble. The estimated state-action values are obtained by fitting a parametric model (e.g., neural networks) to the perturbed datasets using gradient descent. As a result, VIPeR only needs $\mathcal{O}(1)$ time complexity for action selection, while LCB-based algorithms require at least $\Omega(K^2)$, where $K$ is the total number of trajectories in the offline data. We also propose a novel data-splitting technique that helps remove a factor involving the log of the covering number in our bound. We prove that VIPeR yields a provable uncertainty quantifier with overparameterized neural networks and enjoys a bound on sub-optimality of $\tilde{\mathcal{O}}( { \kappa H^{5/2} \tilde{d} }/{\sqrt{K}})$, where $\tilde{d}$ is the effective dimension, $H$ is the horizon length and $\kappa$ measures the distributional shift. We corroborate the statistical and computational efficiency of VIPeR with an empirical evaluation on a wide set of synthetic and real-world datasets. To the best of our knowledge, VIPeR is the first algorithm for offline RL that is provably efficient for general Markov decision processes (MDPs) with neural network function approximation.