 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Scale Transfer Learning for Differentially Private Image Classification
Paper and Code
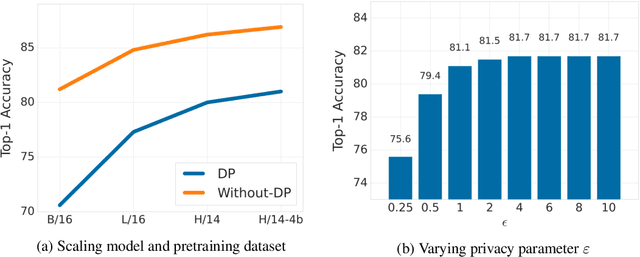
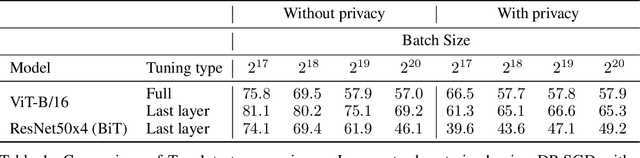
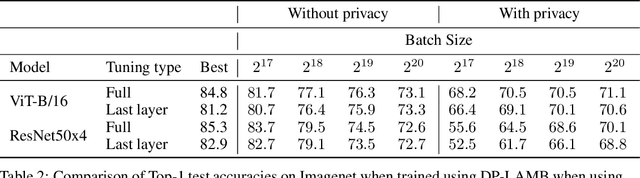
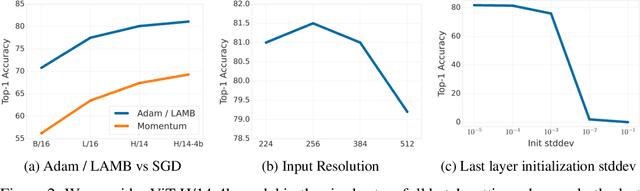
Differential Privacy (DP) provides a formal framework for training machine learning models with individual example level privacy. Training models with DP protects the model against leakage of sensitive data in a potentially adversarial setting. In the field of deep learning, Differentially Private Stochastic Gradient Descent (DP-SGD) has emerged as a popular private training algorithm. Private training using DP-SGD protects against leakage by injecting noise into individual example gradients, such that the trained model weights become nearly independent of the use any particular training example. While this result is quite appealing, the computational cost of training large-scale models with DP-SGD is substantially higher than non-private training. This is further exacerbated by the fact that increasing the number of parameters leads to larger degradation in utility with DP. In this work, we zoom in on the ImageNet dataset and demonstrate that similar to the non-private case, pre-training over-parameterized models on a large public dataset can lead to substantial gains when the model is finetuned privately. Moreover, by systematically comparing private and non-private models across a range of huge batch sizes, we find that similar to non-private setting, choice of optimizer can further improve performance substantially with DP. By switching from DP-SGD to DP-LAMB we saw improvement of up to 20$\%$ points (absolute). Finally, we show that finetuning just the last layer for a \emph{single step} in the full batch setting leads to both SOTA results of 81.7 $\%$ under a wide privacy budget range of $\epsilon \in [4, 10]$ and $\delta$ = $10^{-6}$ while minimizing the computational overhead substantially.