 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Enhancing Representation Learning in Federated Multi-Task Settings
Feb 02, 2026Federated multi-task learning (FMTL) seeks to collaboratively train customized models for users with different tasks while preserving data privacy. Most existing approaches assume model congruity (i.e., the use of fully or partially homogeneous models) across users, which limits their applicability in realistic settings. To overcome this limitation, we aim to learn a shared representation space across tasks rather than shared model parameters. To this end, we propose Muscle loss, a novel contrastive learning objective that simultaneously aligns representations from all participating models. Unlike existing multi-view or multi-model contrastive methods, which typically align models pairwise, Muscle loss can effectively capture dependencies across tasks because its minimization is equivalent to the maximization of mutual information among all the models' representations. Building on this principle, we develop FedMuscle, a practical and communication-efficient FMTL algorithm that naturally handles both model and task heterogeneity. Experiments on diverse image and language tasks demonstrate that FedMuscle consistently outperforms state-of-the-art baselines, delivering substantial improvements and robust performance across heterogeneous settings.
NoT: Federated Unlearning via Weight Negation
Mar 07, 2025Federated unlearning (FU) aims to remove a participant's data contributions from a trained federated learning (FL) model, ensuring privacy and regulatory compliance. Traditional FU methods often depend on auxiliary storage on either the client or server side or require direct access to the data targeted for removal-a dependency that may not be feasible if the data is no longer available. To overcome these limitations, we propose NoT, a novel and efficient FU algorithm based on weight negation (multiplying by -1), which circumvents the need for additional storage and access to the target data. We argue that effective and efficient unlearning can be achieved by perturbing model parameters away from the set of optimal parameters, yet being well-positioned for quick re-optimization. This technique, though seemingly contradictory, is theoretically grounded: we prove that the weight negation perturbation effectively disrupts inter-layer co-adaptation, inducing unlearning while preserving an approximate optimality property, thereby enabling rapid recovery. Experimental results across three datasets and three model architectures demonstrate that NoT significantly outperforms existing baselines in unlearning efficacy as well as in communication and computational efficiency.
Does Combining Parameter-efficient Modules Improve Few-shot Transfer Accuracy?
Feb 23, 2024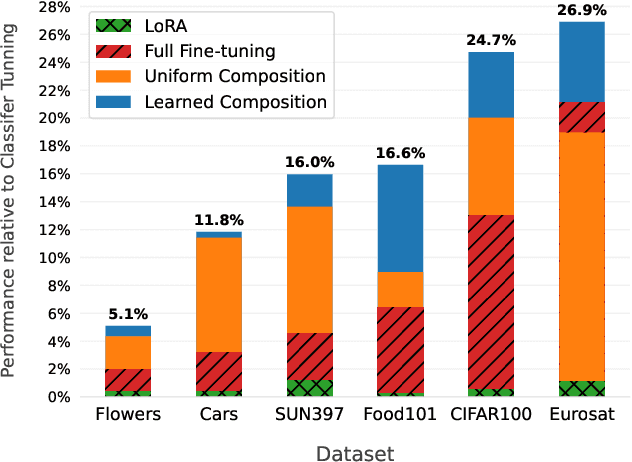
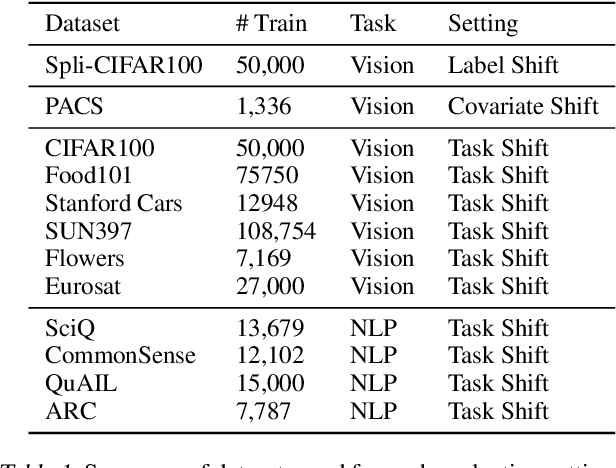
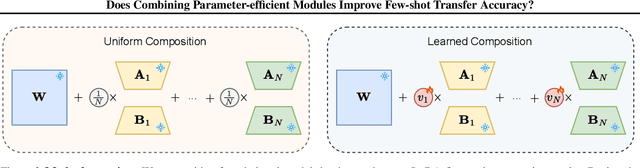
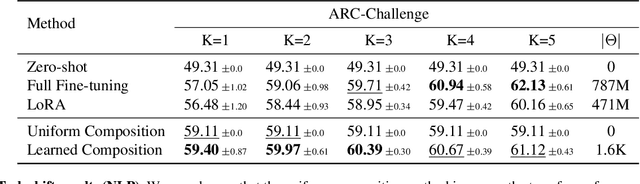
Parameter-efficient fine-tuning stands as the standard for efficiently fine-tuning large language and vision models on downstream tasks. Specifically, the efficiency of low-rank adaptation has facilitated the creation and sharing of hundreds of custom LoRA modules, each trained on distinct data from various downstream tasks. In this paper, we explore the composability of LoRA modules, examining if combining these pre-trained modules enhances generalization to unseen downstream tasks. Our investigation involves evaluating two approaches: (a) uniform composition, involving averaging upstream LoRA modules with equal weights, and (b) learned composition, where we learn the weights for each upstream module and perform weighted averaging. Our experimental results on both vision and language models reveal that in few-shot settings, where only a limited number of samples are available for the downstream task, both uniform and learned composition methods result in better transfer accuracy; outperforming full fine-tuning and training a LoRA from scratch. Moreover, in full-shot settings, learned composition performs comparably to regular LoRA training with significantly fewer number of trainable parameters. Our research unveils the potential of uniform composition for enhancing transferability in low-shot settings, without introducing additional learnable parameters.
Parametric Feature Transfer: One-shot Federated Learning with Foundation Models
Feb 02, 2024In one-shot federated learning (FL), clients collaboratively train a global model in a single round of communication. Existing approaches for one-shot FL enhance communication efficiency at the expense of diminished accuracy. This paper introduces FedPFT (Federated Learning with Parametric Feature Transfer), a methodology that harnesses the transferability of foundation models to enhance both accuracy and communication efficiency in one-shot FL. The approach involves transferring per-client parametric models (specifically, Gaussian mixtures) of features extracted from foundation models. Subsequently, each parametric model is employed to generate synthetic features for training a classifier head. Experimental results on eight datasets demonstrate that FedPFT enhances the communication-accuracy frontier in both centralized and decentralized FL scenarios, as well as across diverse data-heterogeneity settings such as covariate shift and task shift, with improvements of up to 20.6%. Additionally, FedPFT adheres to the data minimization principle of FL, as clients do not send real features. We demonstrate that sending real features is vulnerable to potent reconstruction attacks. Moreover, we show that FedPFT is amenable to formal privacy guarantees via differential privacy, demonstrating favourable privacy-accuracy tradeoffs.
DFML: Decentralized Federated Mutual Learning
Feb 02, 2024In the realm of real-world devices, centralized servers in Federated Learning (FL) present challenges including communication bottlenecks and susceptibility to a single point of failure. Additionally, contemporary devices inherently exhibit model and data heterogeneity. Existing work lacks a Decentralized FL (DFL) framework capable of accommodating such heterogeneity without imposing architectural restrictions or assuming the availability of public data. To address these issues, we propose a Decentralized Federated Mutual Learning (DFML) framework that is serverless, supports nonrestrictive heterogeneous models, and avoids reliance on public data. DFML effectively handles model and data heterogeneity through mutual learning, which distills knowledge between clients, and cyclically varying the amount of supervision and distillation signals. Extensive experimental results demonstrate consistent effectiveness of DFML in both convergence speed and global accuracy, outperforming prevalent baselines under various conditions. For example, with the CIFAR-100 dataset and 50 clients, DFML achieves a substantial increase of +17.20% and +19.95% in global accuracy under Independent and Identically Distributed (IID) and non-IID data shifts, respectively.
Cross Domain Generative Augmentation: Domain Generalization with Latent Diffusion Models
Dec 08, 2023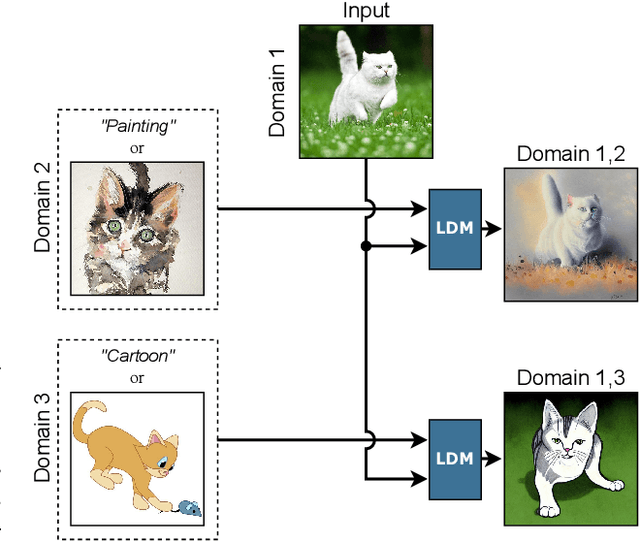



Despite the huge effort in developing novel regularizers for Domain Generalization (DG), adding simple data augmentation to the vanilla ERM which is a practical implementation of the Vicinal Risk Minimization principle (VRM) \citep{chapelle2000vicinal} outperforms or stays competitive with many of the proposed regularizers. The VRM reduces the estimation error in ERM by replacing the point-wise kernel estimates with a more precise estimation of true data distribution that reduces the gap between data points \textbf{within each domain}. However, in the DG setting, the estimation error of true data distribution by ERM is mainly caused by the distribution shift \textbf{between domains} which cannot be fully addressed by simple data augmentation techniques within each domain. Inspired by this limitation of VRM, we propose a novel data augmentation named Cross Domain Generative Augmentation (CDGA) that replaces the pointwise kernel estimates in ERM with new density estimates in the \textbf{vicinity of domain pairs} so that the gap between domains is further reduced. To this end, CDGA, which is built upon latent diffusion models (LDM), generates synthetic images to fill the gap between all domains and as a result, reduces the non-iidness. We show that CDGA outperforms SOTA DG methods under the Domainbed benchmark. To explain the effectiveness of CDGA, we generate more than 5 Million synthetic images and perform extensive ablation studies including data scaling laws, distribution visualization, domain shift quantification, adversarial robustness, and loss landscape analysis.
Normalization Is All You Need: Understanding Layer-Normalized Federated Learning under Extreme Label Shift
Aug 18, 2023Layer normalization (LN) is a widely adopted deep learning technique especially in the era of foundation models. Recently, LN has been shown to be surprisingly effective in federated learning (FL) with non-i.i.d. data. However, exactly why and how it works remains mysterious. In this work, we reveal the profound connection between layer normalization and the label shift problem in federated learning. To understand layer normalization better in FL, we identify the key contributing mechanism of normalization methods in FL, called feature normalization (FN), which applies normalization to the latent feature representation before the classifier head. Although LN and FN do not improve expressive power, they control feature collapse and local overfitting to heavily skewed datasets, and thus accelerates global training. Empirically, we show that normalization leads to drastic improvements on standard benchmarks under extreme label shift. Moreover, we conduct extensive ablation studies to understand the critical factors of layer normalization in FL. Our results verify that FN is an essential ingredient inside LN to significantly improve the convergence of FL while remaining robust to learning rate choices, especially under extreme label shift where each client has access to few classes.