 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoT: Federated Unlearning via Weight Negation
Mar 07, 2025Federated unlearning (FU) aims to remove a participant's data contributions from a trained federated learning (FL) model, ensuring privacy and regulatory compliance. Traditional FU methods often depend on auxiliary storage on either the client or server side or require direct access to the data targeted for removal-a dependency that may not be feasible if the data is no longer available. To overcome these limitations, we propose NoT, a novel and efficient FU algorithm based on weight negation (multiplying by -1), which circumvents the need for additional storage and access to the target data. We argue that effective and efficient unlearning can be achieved by perturbing model parameters away from the set of optimal parameters, yet being well-positioned for quick re-optimization. This technique, though seemingly contradictory, is theoretically grounded: we prove that the weight negation perturbation effectively disrupts inter-layer co-adaptation, inducing unlearning while preserving an approximate optimality property, thereby enabling rapid recovery. Experimental results across three datasets and three model architectures demonstrate that NoT significantly outperforms existing baselines in unlearning efficacy as well as in communication and computational efficiency.
ActAR: Actor-Driven Pose Embeddings for Video Action Recognition
Apr 19, 2022

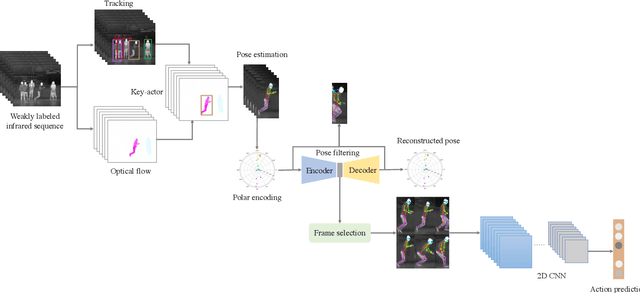
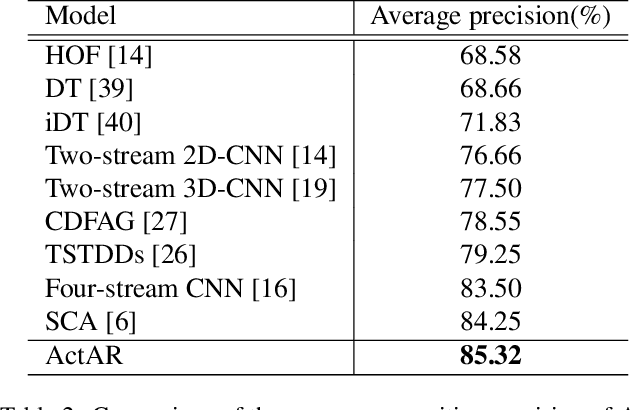
Human action recognition (HAR) in videos is one of the core tasks of video understanding. Based on video sequences, the goal is to recognize actions performed by humans. While HAR has received much attention in the visible spectrum, action recognition in infrared videos is little studied. Accurate recognition of human actions in the infrared domain is a highly challenging task because of the redundant and indistinguishable texture features present in the sequence. Furthermore, in some cases, challenges arise from the irrelevant information induced by the presence of multiple active persons not contributing to the actual action of interest. Therefore, most existing methods consider a standard paradigm that does not take into account these challenges, which is in some part due to the ambiguous definition of the recognition task in some cases. In this paper, we propose a new method that simultaneously learns to recognize efficiently human actions in the infrared spectrum, while automatically identifying the key-actors performing the action without using any prior knowledge or explicit annotations. Our method is composed of three stages. In the first stage, optical flow-based key-actor identification is performed. Then for each key-actor, we estimate key-poses that will guide the frame selection process. A scale-invariant encoding process along with embedded pose filtering are performed in order to enhance the quality of action representations. Experimental results on InfAR dataset show that our proposed model achieves promising recognition performance and learns useful action representations.
A Grid-based Representation for Human Action Recognition
Oct 29, 2020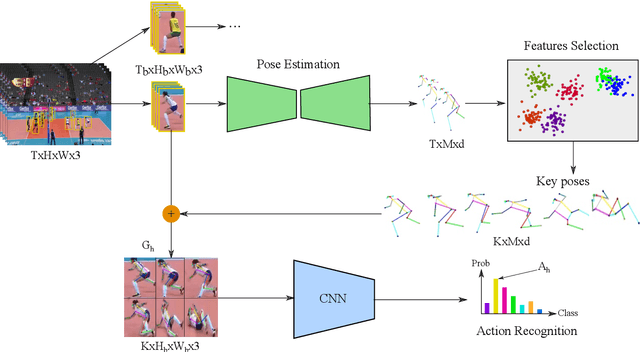
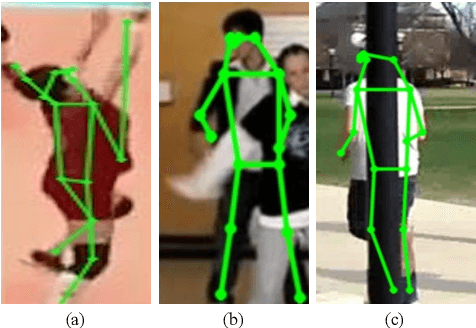


Human action recognition (HAR) in videos is a fundamental research topic in computer vision. It consists mainly in understanding actions performed by humans based on a sequence of visual observations. In recent years, HAR have witnessed significant progress, especially with the emergence of deep learning models. However, most of existing approaches for action recognition rely on information that is not always relevant for this task, and are limited in the way they fuse the temporal information. In this paper, we propose a novel method for human action recognition that encodes efficiently the most discriminative appearance information of an action with explicit attention on representative pose features, into a new compact grid representation. Our GRAR (Grid-based Representation for Action Recognition) method is tested on several benchmark datasets demonstrating that our model can accurately recognize human actions, despite intra-class appearance variations and occlusion challenges.