 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Combining Parameter-efficient Modules Improve Few-shot Transfer Accuracy?
Feb 23, 2024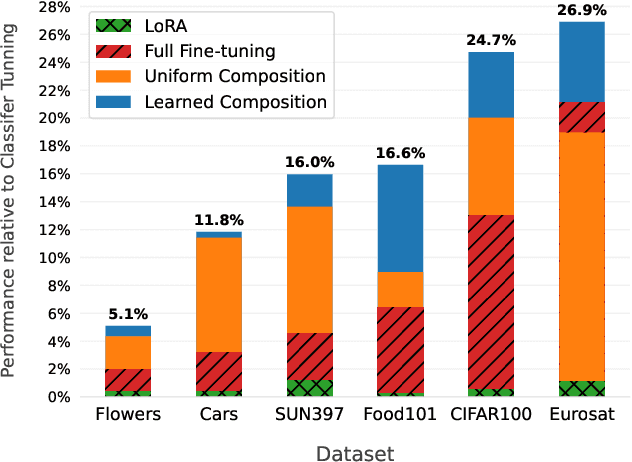
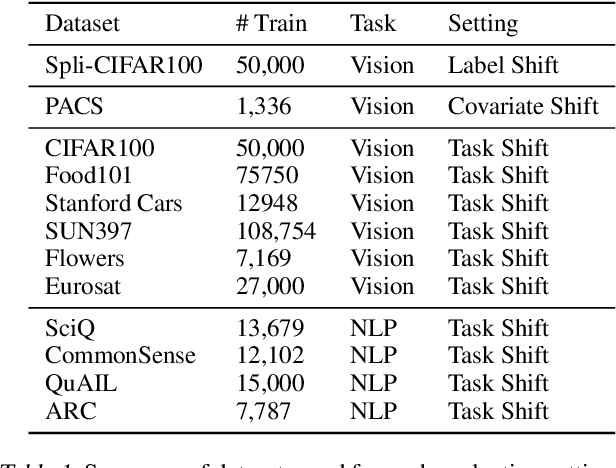
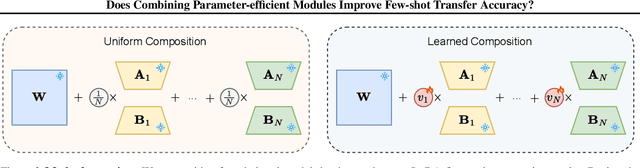
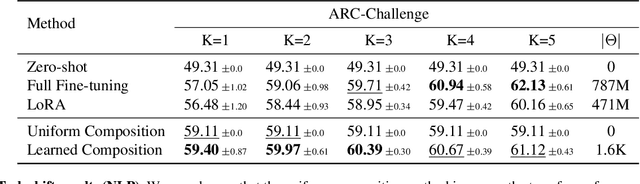
Parameter-efficient fine-tuning stands as the standard for efficiently fine-tuning large language and vision models on downstream tasks. Specifically, the efficiency of low-rank adaptation has facilitated the creation and sharing of hundreds of custom LoRA modules, each trained on distinct data from various downstream tasks. In this paper, we explore the composability of LoRA modules, examining if combining these pre-trained modules enhances generalization to unseen downstream tasks. Our investigation involves evaluating two approaches: (a) uniform composition, involving averaging upstream LoRA modules with equal weights, and (b) learned composition, where we learn the weights for each upstream module and perform weighted averaging. Our experimental results on both vision and language models reveal that in few-shot settings, where only a limited number of samples are available for the downstream task, both uniform and learned composition methods result in better transfer accuracy; outperforming full fine-tuning and training a LoRA from scratch. Moreover, in full-shot settings, learned composition performs comparably to regular LoRA training with significantly fewer number of trainable parameters. Our research unveils the potential of uniform composition for enhancing transferability in low-shot settings, without introducing additional learnable parameters.